User Guides - Memory Allocation
By Alexander Yee
(Last updated: February 4, 2019)
y-cruncher has had support for advanced forms of memory allocation since version 0.7.1. It first started with large and locked pages. Now there is basic support for NUMA awareness.
As of version 0.7.3, y-cruncher supports:
- Large pages that (on x86) have page sizes of 2 MB rather than 4 KB.
- Locked pages that are locked in memory and cannot be paged out to disk.
- Interleaved pages that are spread out across multiple NUMA nodes.
These configurations are not mutually exclusive and it's usually possible to do a combination of them.
The default behavior of y-cruncher depends on whether it detects a NUMA architecture:
- On systems with only one NUMA node, y-cruncher will automatically try to use large pages and lock them in memory.
- On systems with multiple NUMA nodes, y-cruncher will attempt to spread out the pages across all the NUMA nodes in a randomized pattern. It will also attempt to lock the pages into memory, but it will not try to use large pages.
All 3 features have system requirements for them to function properly. By default, y-cruncher will gracefully fall back should it fail to enable any particular feature.
Large Pages:
Large pages can improve performance by increasing the efficiency of the Translation Lookaside Buffer (TLB). It is commonly used in large-scale server and database applications that are very memory intensive.
The default page size for x86 is 4 KB. Large page sizes for x86 include 2 MB and 1GB. But y-cruncher only supports 2 MB large pages.
Large page support was the original motivation for the entire memory allocation support in y-cruncher. Initially, this optimization turned out to be a miss as performance improvements had largely been negligible. But things have changed in the post-Meltdown world.
In the post-Spectre/Meltdown world, the Kernel Page Table Isolation (KPTI) mitigation has a non-negligible performance penalty on y-cruncher for certain processors. Large computations have large memory footprints and thus a lot of page table entries. When these get invalidated by KPTI, the cost to bring them back in can be significant. Large pages can significantly reduce this penalty as pages are much larger and thus there fewer pages that need to be brought back into the page tables.
On both Windows and Linux, OS support is required:
- On Windows, the administrator access with the "SeLockMemoryPrivilege" privilege is required.
- On Linux, large pages must be enabled.
- For both Windows and Linux, there must be a sufficient amount of available large pages or contiguous memory.
Locked Pages:
Locked pages are memory pages that are locked in memory and cannot be swapped out to disk. This is useful for realtime applications that cannot accept the performance hit of paging to disk.
Locked page support was added to solve the problem of overzealous paging on Linux when running swap mode computations. At some point between Ubuntu 14.10 and Ubuntu 15.10, there was a change to the kernel that makes the OS (by default) aggressively swap out processes even when there is enough memory to hold it all in ram. This happens only in swap mode - possibly a consequence of the OS trying to increase the disk cache.
The problem is that y-cruncher's performance can degrade by orders of magnitude if even a small part of its memory is paged out to disk. When y-cruncher allocates memory, it expects it to stay in memory, and it uses it like it is physical memory. When such access patterns are applied to disk as a result of paging, only bad things can happen. If the page file is located on the same mechanical hard drive that the system resides on, it usually leads to a system freeze which can only be fixed by a hard shutdown. Things are better for SSDs, but that's just treating the symptoms rather than the cause.
It's possible to configure the OS to not swap by either disabling the pagefile or setting the swappiness to zero. y-cruncher attempts to solve it transparently by automatically locking pages into memory if possible. Ultimately, the OS is trying to be too smart. While this is beneficial for "normal" programs, it gets in the way of specialized applications like y-cruncher which manually handle disk swapping.
This problem currently does not exist on Windows. Unlike Windows, the Linux kernel does not respect the raw I/O flag (O_DIRECT) with regards to completely disabling the disk cache for a particular file handle/descriptor.
Why bother with swap mode at all? Why not just let the OS do it for you via paging? This is answered in the swap mode FAQ.
On Linux, privilege elevation is needed for large pages. Interestingly on Windows, the "SeLockMemoryPrivilege" privilege is not needed. Though it has yet to be tested to see if these pages are actually locked.
4 x Opteron 8356 @ 2.3 GHz - 250 million digits of Pi Windows Server 2016 |
|
| Memory Distribution | Time (seconds) |
| Default Allocator | 123.274 |
| All on One Node | 131.539 |
| Interleave 2 Nodes | 83.149 |
| Interleave 3 Nodes | 77.860 |
| Interleave 4 Nodes | 63.502 |
| Node Interleaving via BIOS | 65.458 |
Performance scaling by varying the amount of interleaving. Note the 2x improvement with full interleaving.
4 x Opteron 8356 @ 2.3 GHz - 250 million digits of Pi Ubuntu Linux 17.04 |
||||
Sockets Enabled: (Cores) |
1 (4 cores) |
2
(8 cores) |
3
(12 cores) |
4
(16 cores) |
Default Allocator |
211.471 | 130.113 | 139.744 | 130.416 |
Node Interleave (numactl) |
211.667 | 115.509 | 93.839 | 64.361 |
Node Interleave (y-cruncher v0.7.3) |
216.257 | 121.379 | 93.259 | 64.955 |
Performance scaling as the number of sockets being used is increased. Memory is allocated only on the nodes that have its socket enabled. 1-to-4 socket scaling is only 1.6x with default allocation that places all memory on one node. With interleaving, it jumps to 3.3x for 4 sockets.
Interleaved Pages:
Interleaved pages is intended to solve the problem of bandwidth traffic imbalance on modern multi-socket systems that are heavily NUMA (Non-Uniform Memory Access).
The idea behind node-interleaving is to spread out the memory across all the NUMA nodes so that they are all accessed equally as opposed to all the traffic being concentrated on one node. This increases the aggregate bandwidth that's available to the system.
Speedups of normal allocation vs. interleaved NUMA can be larger than 2x on systems with strong NUMA topologies. (see tables to the right)
Historically, node-interleaving has had both hardware and software support. Most multi-socket machines have a BIOS option to enable node-interleaving. On Linux, the numactl package is a software approach that can run applications with node-interleaving.
However, these existing methods tend to have problems:
- Node-interleaving is disabled by default in the BIOS. But most users of multi-socket machines have only remote access through a virtual machine so they have no ability to access the BIOS settings.
- On Linux, numactl is usually not as useful because:
- It tends to not be installed and users often don't have the permissions to install it.
- Uninformed users don't know what it is, or don't remember to use it.
- When numactl is used, it often produces very poor quality interleaving.
- In Windows, there are no options to interleave memory. Enabling node-interleaving in the BIOS will cause issues with imbalanced processor groups when the total number of logical cores exceeds 64 and is not a multiple of 64.
Node interleaving is enabled by default when it detects multiple NUMA nodes in the system. So no user intervention is needed.
The quality of the interleaving is very high on Windows and the dynamically-linked Linux binaries. The statically-linked Linux binaries aren't quite as good since the libnuma library is not available. So it's better to run the dynamically-linked binaries if you're able to do so.
Like the parallel frameworks, memory allocations are implemented behind an interface. So multiple allocators are available to be chosen by the user.
For all allocators, the allocated memory is pre-faulted and committed to memory to prevent page-faults during the computation as well as segfaults from overcommiting.
Furthermore, the memory is filled with random data to prevent the operating system from trying compress the memory. (I'm looking at you, Windows 10 Superfetch.)
For most allocators, this process of pre-faulting and commiting memory is lightly parallelized. "Lightly" here means, enough to get a speedup, but not so much to cause resource contention in the kernel. (Windows 10 has been observed to undergo some sort of "catastrophic lock contention" when too many threads page fault at once.)
C malloc():
Use the C malloc() function. Not much to be said here. Because this is a basic C function, there are no options for large or locked pages.
Internally, the memory will still be page-aligned and pre-faulted to maintain consistency with the other allocators.
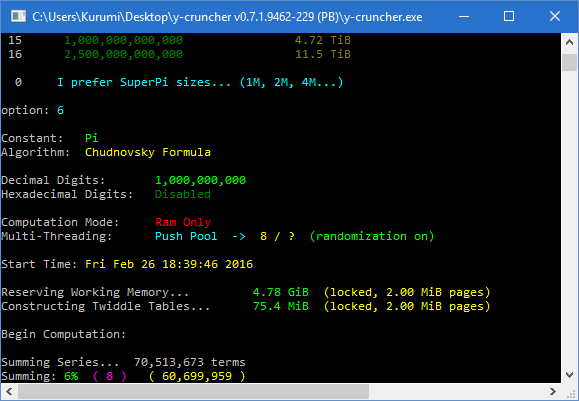
WinAPI VirtualAlloc (Windows) / Posix mmap (Linux):
Use the system call for allocating new pages. On Windows it uses VirtualAlloc() and on Linux it uses mmap().
This allocator is the default when y-cruncher only detects one NUMA node.
On both Windows and Linux, this option supports both large and locked pages. On Linux, each are supported independently from each other. On Windows, all large pages are automatically locked in memory by the OS.
Be default, this allocator will attempt to enable both large and locked pages. Should they fail, the computation will proceed anyway without them. There are options to disable these features or error out should they fail to enable.
When large pages are enabled, there will be an indicator next to the memory allocation text that says, "2.00 MiB pages" or "large pages".
When locked pages are enabled, there will be an indicator next to the memory allocation text that says, "locked".
Node Interleaving:
This option provides support for interleaving pages across NUMA nodes with page granularity.
There are two modes of interleaving: round-robin and hashing
- Round-Robin simply assigns pages across all the NUMA nodes in a cyclic pattern.
- Hashing randomly assigns the pages to the NUMA nodes using some uniform hash algorithm.
Round-Robin mode is simpler and guarantees uniform distribution of memory across all the NUMA nodes. But it (theoretically) can suffer performance degradation from super-aligned access patterns that are typical of large FFTs. However, there is currently insufficient data to show whether this theoretical performance degradation actually takes place to an observable extent.
By default, y-cruncher will use all the NUMA nodes that it can detect. But you can also specify which nodes. Nodes can be specified multiple times which has the effect of allowing the user to unevenly distribute the pages across the nodes.
Locked pages are supported in combination with page interleaving. But large pages are not. When interleaving, it is best to use as fine a granularity as possible. This makes large pages less appealing. Furthermore, it does not appear to be possible to interleave large pages on Windows.
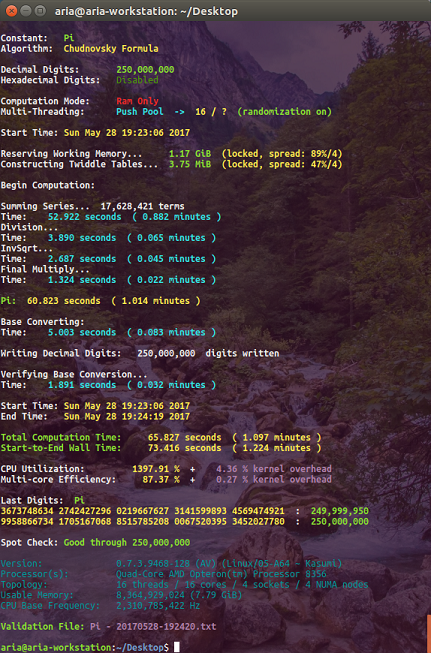
When using this memory allocator, y-cruncher will display a "spread" in the memory allocation indicator. This "spread" is a value between 0 and 100% that roughly describes how well the memory has been spread out across the nodes. The number after the slash is the number of nodes involved.
- 100% means the memory is perfectly distributed across the number of nodes indicated.
- 0% means the memory is all on one node.
- Values above 90% are considered good.
The "spread" value is calculated by taking the standard deviation of the number of bytes on each node and scaling it into a range of 0 - 100%.
On Linux, this "spread" indicator is not available for the statically-linked binaries since libnuma is required to query which node a page has been mapped to.
Implementation Details:
The method of allocation and interleaving differs between Windows and Linux.
On Windows it is done by first reserving the virtual address space, then making a pass over each of the pages to explicitly pre-fault and bind them onto the desired NUMA nodes. This approach is very reliable and usually achieves 99% spread when there is sufficient memory on all the nodes.
On Linux, they are mmap()'ed all at once and then pre-faulted from threads that are pinned to the desired NUMA node. This approach relies on the first-touch allocation policy and is not as reliable as the Windows approach. It rarely gets over 90% spread, but it works without a libnuma dependency for the statically-linked binaries.
The dynamically-linked Linux binaries have the option to mbind() the pages to their desired nodes. However, this behavior is disabled by default since it has been observed to cause spurious failures later in the computation for unknown reasons.
Node Interleaving (libnuma):
This option is an alternate implementation of the Node Interleaving using the libnuma library instead of manual interleaving. This option is only available in Linux and only for the dynamically-linked library. There is also no support for selecting the page-mapping since that's all handled internally by the libnuma library.
The quality of the interleaving in libnuma is usually of higher quality than by manual interleaving. The reason why the manual interleaving allocator exists at all is because it is has no dependency on libnuma and usable on Windows where there is no support for OS software-based interleaving at all.
When y-cruncher detects multiple NUMA nodes in the system, it will default to one of the Interleaved NUMA allocators.
Requirements for Locked Pages:
None. Interestingly, the "SeLockMemoryPrivilege" token doesn't seem to be needed.
Requirements for Large Pages:
- You need to have the "SeLockMemoryPrivilege" token. This privilege is disabled for all users by default. You will need to enable it manually.
- y-cruncher needs to be running as an administrator.
- There needs to be enough contiguous physical memory in the system.
Enabling SeLockMemoryPrivilege:
"SeLockMemoryPrivilege" is disabled for all users by default. So you will likely need to enable it manually.
Instructions for enabling it using the Group Policy Editor can be found here: https://msdn.microsoft.com/en-us/library/ms190730.aspx
If your version of Windows is a Home Edition and does not have the Group Policy Editor, you can also enable it by running the following program:
Enable "SeLockMemoryPrivilege" on Windows:
(Update August 2018: This binary no longer seems to work on the latest Windows 10. Something has changed in the OS.)
Run y-cruncher as an Administrator:
Right-click the program and select "Run as administrator". You may get a UAC warning depending on your settings.
Make sure there is sufficient contiguous physical memory:
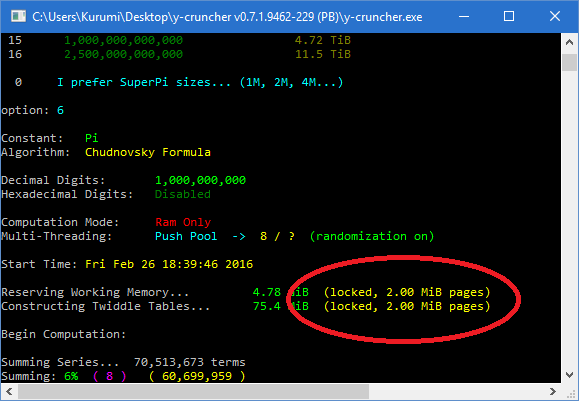
There's no way to tell other than to try and run the desired computation. If it works, then it works. If not, then you may need to try rebooting the system.
Windows can only allocate large pages when there is sufficient contiguous memory. But it does not appear to be able to defragment the memory on the fly. This means that the only way to defragment the memory is to reboot the system.
Support for large pages in Windows is unfortunately very flaky and there is no guarantee that it will ever work.
When large and locked pages are working, it will look like the image to the right. Note the presence of the "(locked, 2.00 MiB pages)" tag next to the memory sizes.
When it doesn't work, the tag will be missing. If you are missing the privilege, there will be a red warning that reads,
Unable to acquire the permission, "SeLockMemoryPrivilege".
Large pages and page locking will not be possible.
This will happen if you don't run y-cruncher as administrator or if the user account doesn't have the "SeLockMemoryPrivilege" token.
If you don't see the warning, and the tag is missing, then there isn't enough contiguous physical memory. So you will need to try rebooting.
Requirements for Locked Pages:
- y-cruncher needs to be running with privilege elevation.
- There needs to be sufficient memory available.
Requirements for Large Pages:
- Large pages are either reserved or enabled transparently in the OS.
- There needs to be sufficient memory available.
Run y-cruncher with privilege elevation:
sudo ./y-cruncher
Enable large pages in the OS:
Install the hugepages package:
sudo apt-get install hugepages
Enable large pages:
sudo hugeadm --pool-pages-max=DEFAULT:30G
(Replace "30G" with however much you want. Don't worry about setting it too high, it will clip down to what is available.)
At this point, y-cruncher will be able to use large pages provided that the physical memory space isn't too fragmented. This behavior is the same as in Windows, except that it's more likely to succeed in Linux. Perhaps Linux attempts to defragment the physical memory.
These instructions enable what is called "Transparent Huge Pages". If it ever fails, y-cruncher will gracefully fallback to normal pages. There are other ways to enable large pages. For example, they can be reserved at startup which prevents them from being fragmented. Should you decide to go this route, be aware that y-cruncher does not properly detect memory when huge pages are reserved this way. So you may get warnings.
For example, suppose you have 32 GB of ram and you reserve 28 GB of it for large pages. This can be done either at startup or by running:
sudo hugeadm --pool-pages-min=DEFAULT:28G
(Note the bold "min" to distinguish it from the earlier command.)
Now when you run y-cruncher, it will think that you have less than 4 GB of memory left since it can only detect memory that's available for normal pages. So if you try compute 5 billion digits of Pi (which requires 24GB of memory), it will spit warnings at you saying there isn't enough memory. But if you ignore all those warnings and try to run it anyway, it will work fine.
Just as with Windows, there will be a tag indicating that large and/or locked pages are working. Likewise, there will be a warning when y-cruncher doesn't have sufficient privileges to lock pages in memory.