Back To:
AV False Positives: (October 24, 2017) - permalink
It has come to my attention that the "y-cruncher.exe" launcher binary in Windows has been getting flagged by some virus scanners. This has been the case for at least the last several releases.
This is currently under investigation. Unfortunately, I'm not an expert in this field. So I don't really know what exactly is tripping up the AV heuristics. At this time, the only fix I've found will break compatibility with older versions of Windows.
In case anybody is willing to help, the source code for the launcher binary has been released on GitHub. Compiling it using the provided Visual Studio project will produce the binary that turns up false positive under said virus scanners.
Version 0.7.4: (October 14, 2017) - permalink
A new version is out with some changes aimed at addressing the memory bottleneck on Ryzen 7 and Skylake X.
While the changes in this release help alleviate the memory bottleneck, they fall well short of actually solving it. The memory bandwidth problem is here to stay and is expected to get worse if hardware trends continue as they have been for the past decade.
The memory bandwidth problem has actually been an ongoing cat-and-mouse game since the very first version of y-cruncher. Whenever the memory bottleneck catches up in a new generation of hardware, an optimization in y-cruncher is made to push it away again. But it looks like the cat is finally winning on the latest generation of desktop processors - especially the HCC Skylake X line.
Updates on Skylake X and Threadripper: (August 15, 2017) - permalink
This is a follow up to my analysis on the Skylake X processors as well a few notes about AMD Threadripper.
I've also released a patch (v0.7.3.9474) to fix some issues with the Linux binaries on Threadripper and Epyc.
Skylake X Follow Up:
It has been confirmed with benchmarks that all the Skylake X desktops have full-throughput FMA. This directly contradicts Intel's pre-release information. Subsequently, all the pre-release reviewers apparently got their information from the same inaccurate source from Intel. So if you are looking to purchase a Skylake X system for the purpose of AVX512, you do not need to spend $1000 to get the Core i9 7900X for the full AVX512. Either of the 6 or 8 core models (7800X and 7820X) will do.
The phantom throttling issues on Gigabyte motherboards still exist even after multiple BIOS updates. While there has been some change in the behavior of the throttling, little has been done to actually solve it. So manual intervention is still necessary to counter the throttling. The problem of throttling in general seems to be even worse in Linux. But I have yet to investigate this in depth. And as of now, I don't even know if the throttling in Linux is a phantom throttle or a normal throttle.
I look forward to see what phantom throttling looks like under the VTune profiler.
The "unknown bottlenecks" that I mentioned before is the L3 cache mesh. The L3 cache mesh on Skylake X only has about half the bandwidth of the L3 cache on the previous generation Haswell/Broadwell-EP processors. The Skylake X L3 cache is so slow that it's barely faster than main memory in terms of bandwidth. So for all practical purposes, it's as good as non-existant.
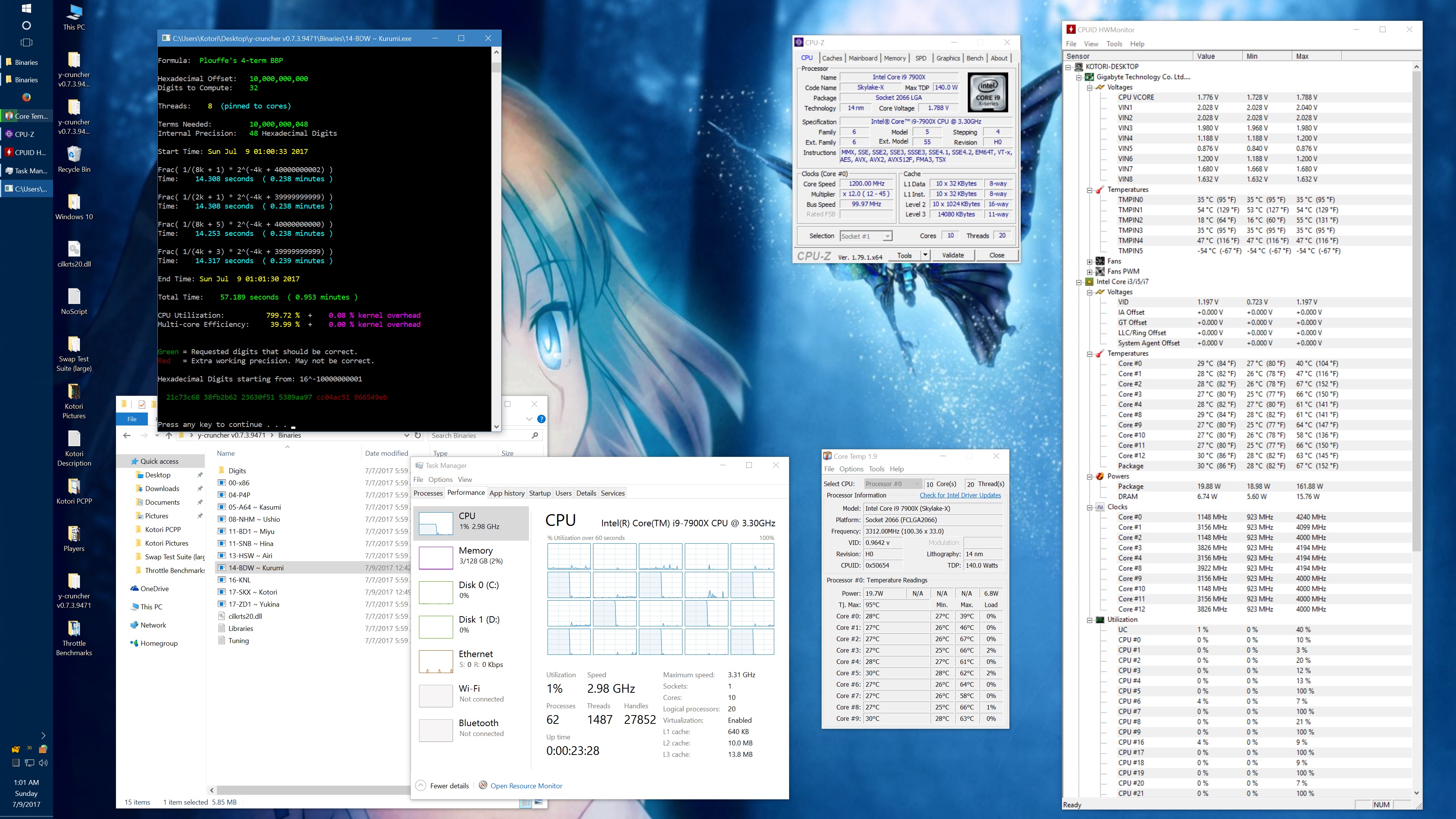
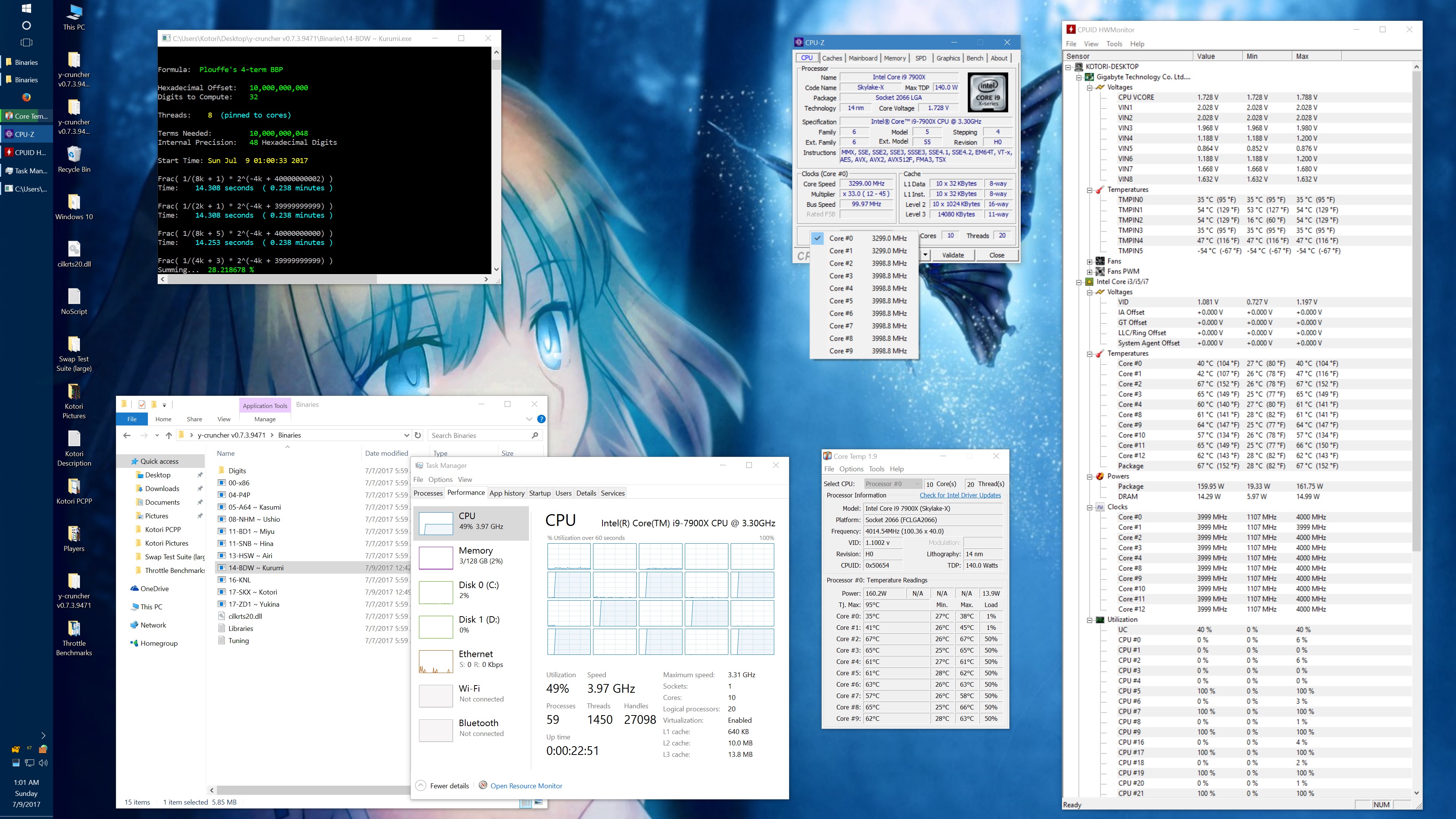
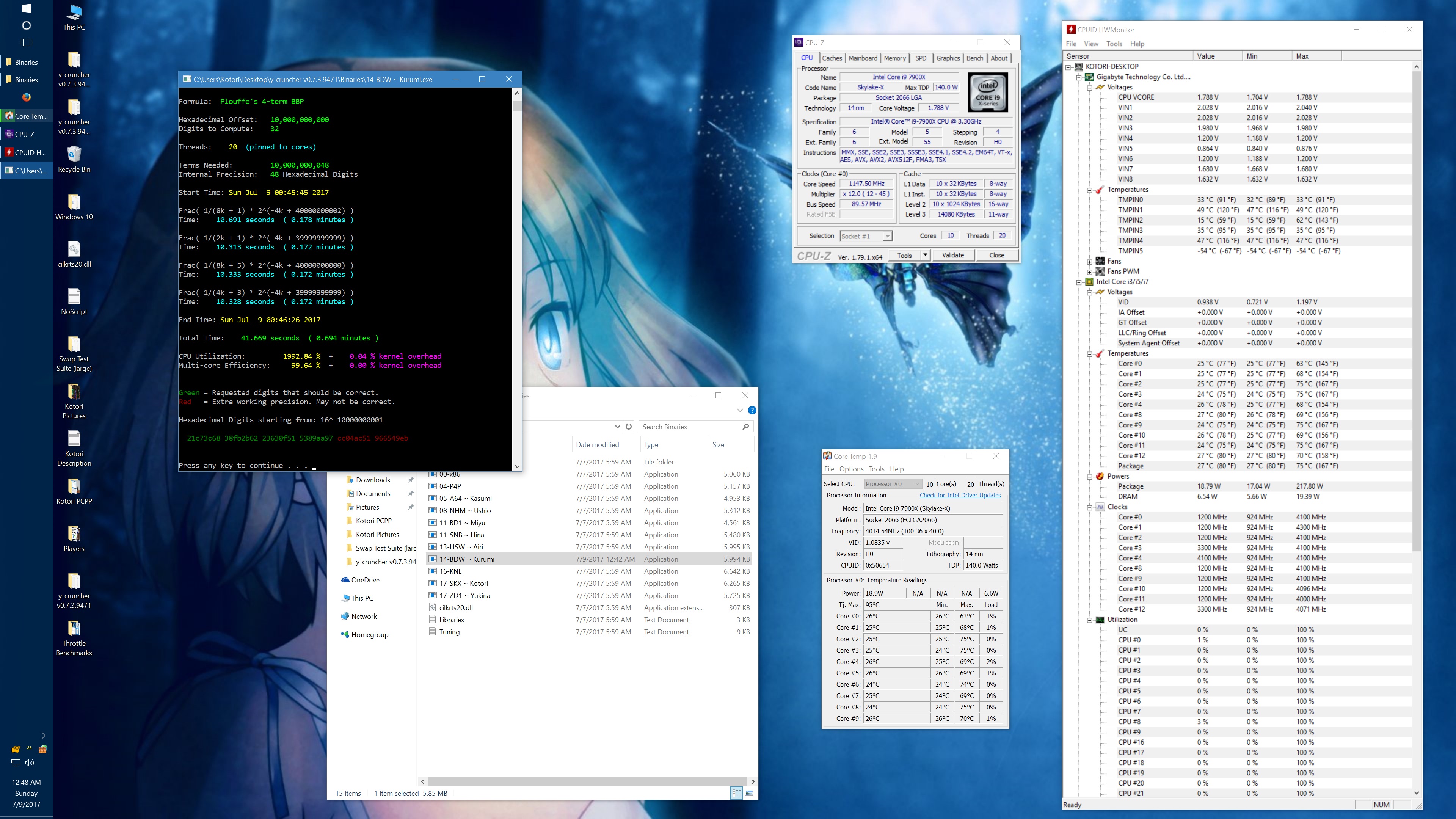
To illustrate how bad the L3 mesh is, this is what happened when I overclocked it:
1 billion digits of Pi - Core i9 7900X @ 3.8 GHz y-cruncher v0.7.3 - Times in Seconds |
||||||
| AVX2 (14-BDW) | AVX512 (17-SKX) | |||||
| Memory\Mesh | 2.4 GHz | 2.8 GHz | 3.2 GHz | 2.4 GHz | 2.8 GHz | 3.2 GHz |
| 2133 MHz | 51.624 | 51.053 | 50.448 | 45.468 | 44.870 | 44.291 |
| 2666 MHz | 49.102 | 48.311 | 47.812 | 41.434 | 40.700 | 39.927 |
| 3400 MHz | 47.233 | 46.150 | 45.451 | 38.405 | 37.228 | 36.355 |
That's a 25% speedup just from overclocking the cache and memory while keeping the CPU frequency locked at 3.8 GHz. And we still haven't reached the point of diminishing returns. Above 3.2 GHz cache and 3400 MHz memory, the system started showing signs of instability. But I didn't try very hard to get it stable.
Overclocking the cache and memory also led to a disproportionally large increase in CPU temperatures and power consumption. This is probably due to the secondary effects of lifting the cache/memory bottlenecks which allow the code to run much more efficiently and intensively than before.
Running the L3 cache mesh at 3.2 GHz managed to trigger a small but noticeable amount of phantom throttling in a BIOS profile which I thought was resistant to it. So I actually had to redo all the benchmarks with an updated profile. In my previous phantom throttling test with the BBP benchmark, the throttling only affected the AVX512 workload. In this case, it affected both the AVX2 and AVX512 loads - but more so on the AVX512. The AVX2 runs never broke 220W on the CPU. But the AVX512 runs were consistently pulling around 270 - 320W. Prior to this, I had never observed any throttling below 260W. Assuming these power draw readings are reliable, it seems to suggest that the phantom throttling isn't entirely dependent on the total CPU power draw. So there are likely other (unknown) factors involved.
From the software optimization standpoint, the cache bottleneck brings a new set of difficulties. The L2 cache is fine. It is 4x larger than before and has doubled in bandwidth to keep up with the AVX512. But the L3 is useless. The net effect is that the usable cache per core is halved compared to the previous Haswell/Broadwell generations. Furthermore, doubling of the SIMD size with AVX512 makes the usable cache 4x smaller than before in terms of # of SIMD words that fit in cache.
The Skylake Purley binary (17-SKX) for y-cruncher v0.7.3 is currently tuned to 1 MB cache/logical-core. But since the L3 is useless, it should be 512 KB/logical-core. However, fixing this isn't as simple as changing one number in the source code and recompiling. The effect of the cache being "4x smaller" unfortunately puts it outside the domain of y-cruncher's tuning parameters. Fixing this to allow y-cruncher to run well on such a small cache will probably require uprooting a not-so-insignificant amount of code.
AMD Threadripper and NUMA:
Threadripper has been released and has brought 16-core processors to the consumer market. And there has been a lot of the talk has been about the NUMA the various memory modes, and how they affect performance.
I currently don't have a Threadripper machine to play with nor do I intend to buy/build one (I'm way over-budget on hardware this year). But as far as I can tell from the reviews, it's no different from multi-socket NUMA which has already existed for years:
y-cruncher has been NUMA-aware since v0.7.1. And starting from v0.7.3, it has been smart about allocating memory on NUMA systems.
y-cruncher prefers high bandwidth and is relatively insensitive to memory latencies. So node-interleaving is almost always better.
So in other words, it should not matter which memory mode you choose on Threadripper and Epyc since y-cruncher will automatically do the right thing. But if you wish to tinker with the memory allocation settings within y-cruncher, you can do that within the "Custom Compute" menu. (Further reading: Memory Allocation)
To summarize, no major update is needed for y-cruncher to support Threadripper's NUMA modes. Only a patch was needed to make it properly detect the NUMA topology on Threadripper and Epyc under Linux. The Windows binaries should be fine without the patch.
Other Thoughts:
This has been a crazy year and it's not done yet as we're expecting the high-core-count Skylake X chips to arrive in September.
Overall, y-cruncher has actually been better prepared for Ryzen/Threadripper than Skylake X/AVX512. AMD Zen didn't bring anything new in terms of processor features. So little needed to be done on the low-level optimization side. The NUMA stuff is something that y-cruncher already supported since multi-socket servers has always been one of y-cruncher's intended use cases.
The only unexpected bottleneck with Zen was the memory bandwidth - one that was largely unactionable.
On the other hand, Skylake X brings AVX512 which led to a massive domino effect of bottlenecks and performance issues which I was completely unprepared for.
Skylake X and AVX512: (July 6, 2017) - permalink
Let's talk about Skylake X and AVX512. Because everyone's been waiting for this. Since there's currently a lack of AVX512 benchmarks and stress tests. And because of that, I've had at least half a dozen people and organizations contact me about y-cruncher's AVX512.
Okay... some AVX512 benchmarks already existed. SiSoftware Sandra had some support. And my little-known FLOPs benchmark did too. But people either weren't aware of them, or wanted more. And by advertising y-cruncher's internal AVX512 support for at least a year now, I basically brought this on myself.
So let's get to the point. Unfortunately, AVX512 will not bring the "instant massive performance gain" that a lot of people were expecting. Realistically speaking, the speedups over AVX2 seem to vary around 10 - 50% - usually on the lower end of that scale. While the investigation is on-going, there are some known factors:
Not all Skylake X and Skylake Purley processors will have the full AVX512 capability:
While this reason doesn't apply to my system, it's worth mentioning it anyway.
Architecturally, Skylake X retains Skylake desktop's architecture with 2 x 256-bit FMA units. In Skylake X, those two 256-bit FMA units can merge to form a single 512-bit FMA. On the processors with full-throughput AVX512, there is also a dedicated 512-bit FMA - thereby providing 2 x 512-bit FMA capability.
However, that dedicated 512-bit FMA is only enabled on the Core i9 parts. The 6-core and 8-core Core i7 parts are supposed to have it disabled. Therefore they only have half the AVX512 performance.
It's worth mentioning that there is a benchmark on an engineering-sample 6-core Core i7 that shows full-throughput AVX512 anyway. However, engineering sample processors are not always representative of the retail parts.
So as of this writing, I still don't know if the 6 and 8-core Skylake X Core i7's have the full AVX512. The only Skylake X processor I have at this time is the Core i9 7900X which is supposed to have the full AVX512 anyway. (and indeed it does based on my tests)
Update (July 14, 2017):
Carsten Spille from www.pcgameshardware.de has notified me that the retail Core i7 7800X does in fact have full-throughput AVX512. This goes against all the reviews that have repeatedly stated that only the Core i9s have the full AVX512. So far, Intel has not commented on this.
"Phantom throttling" of performance when certain thermal limits are exceeded:
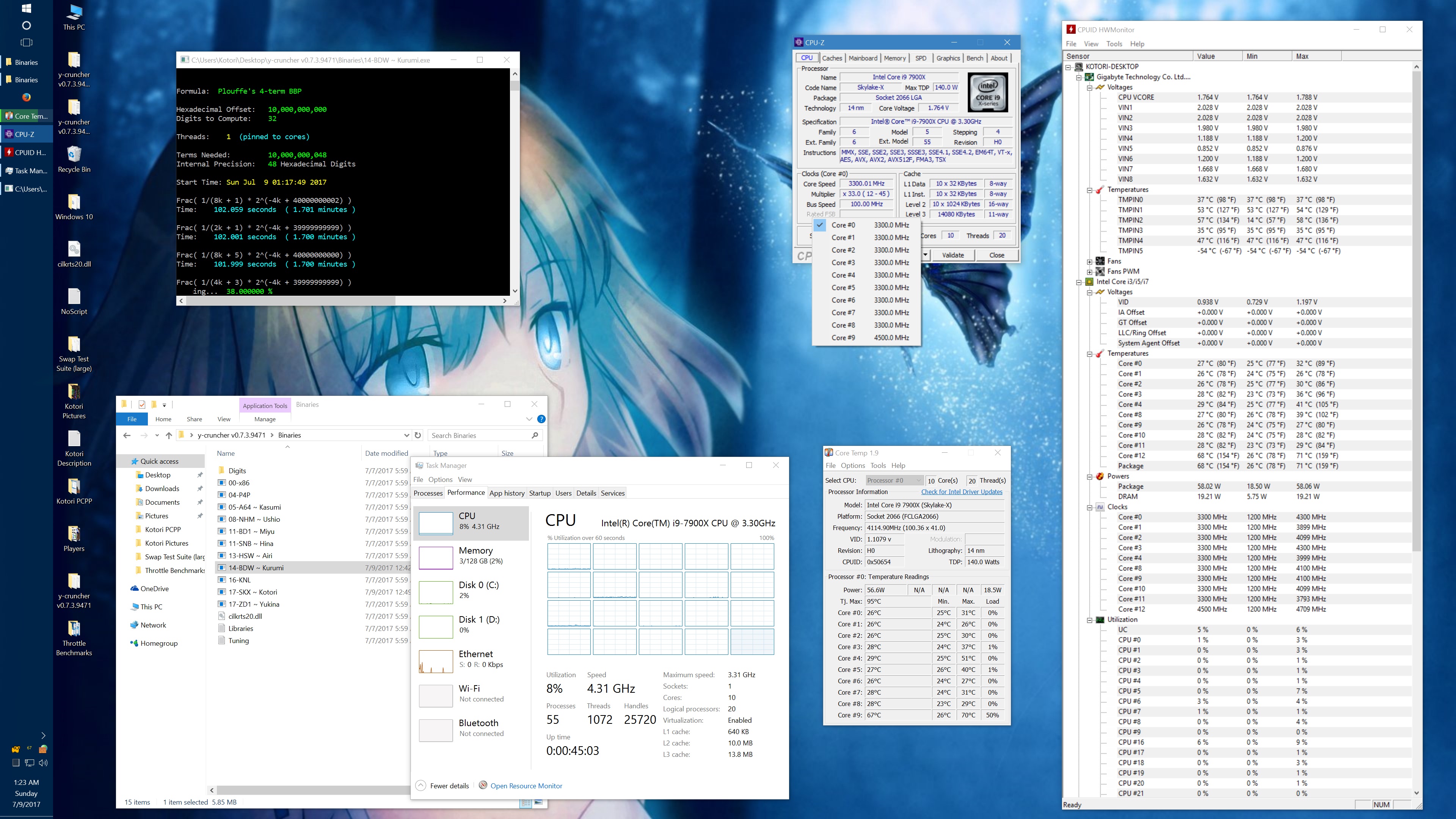
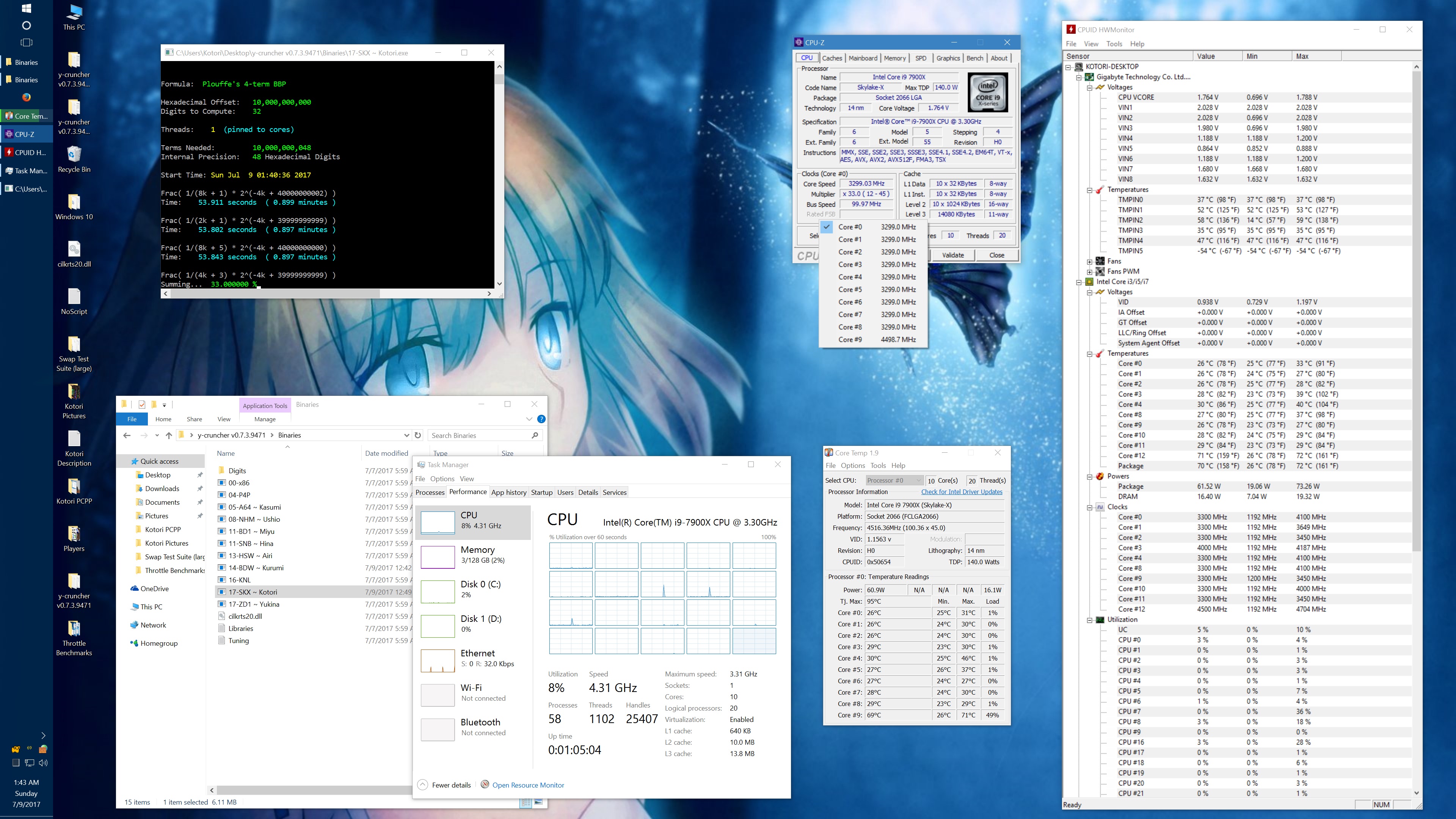
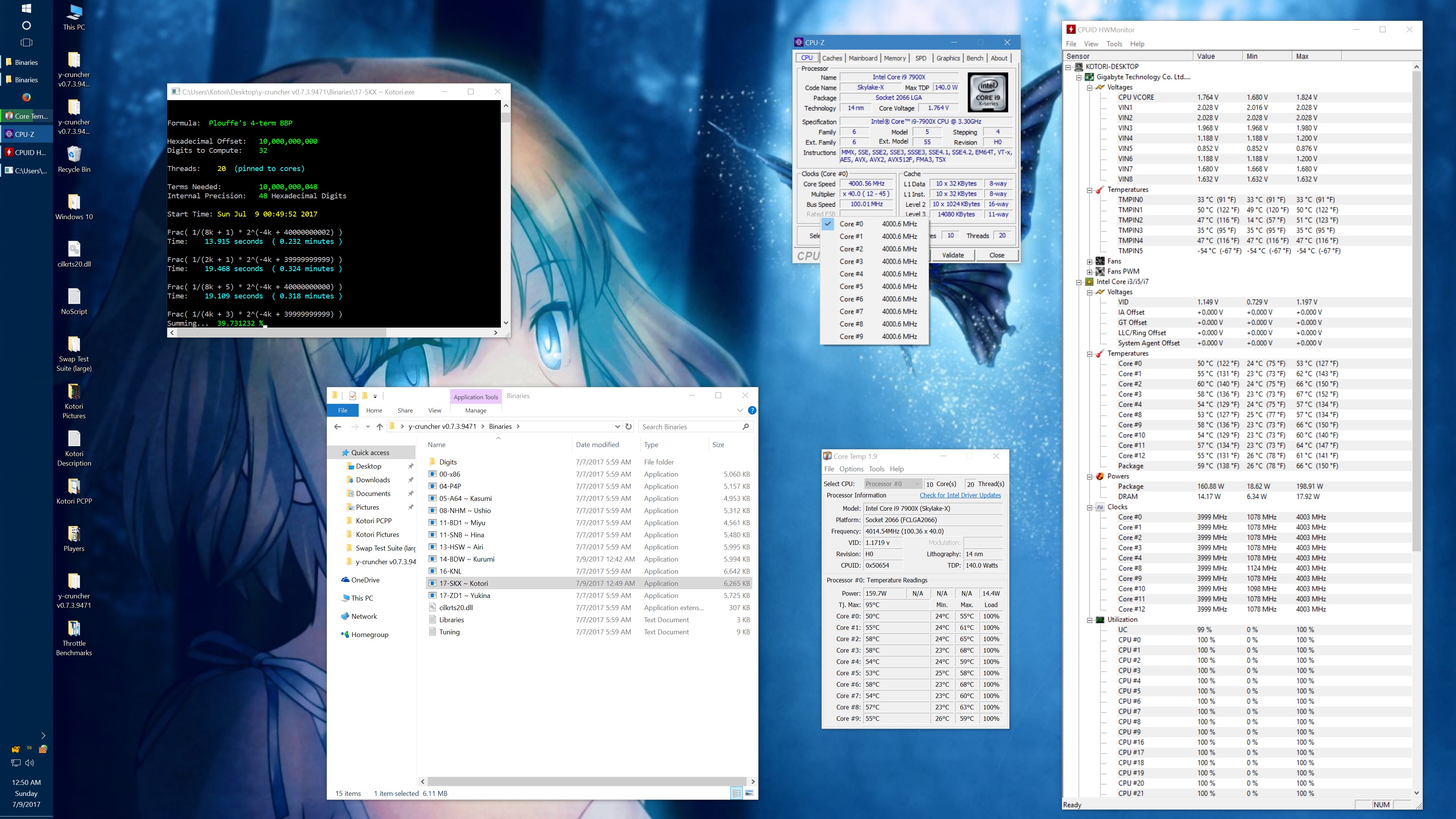
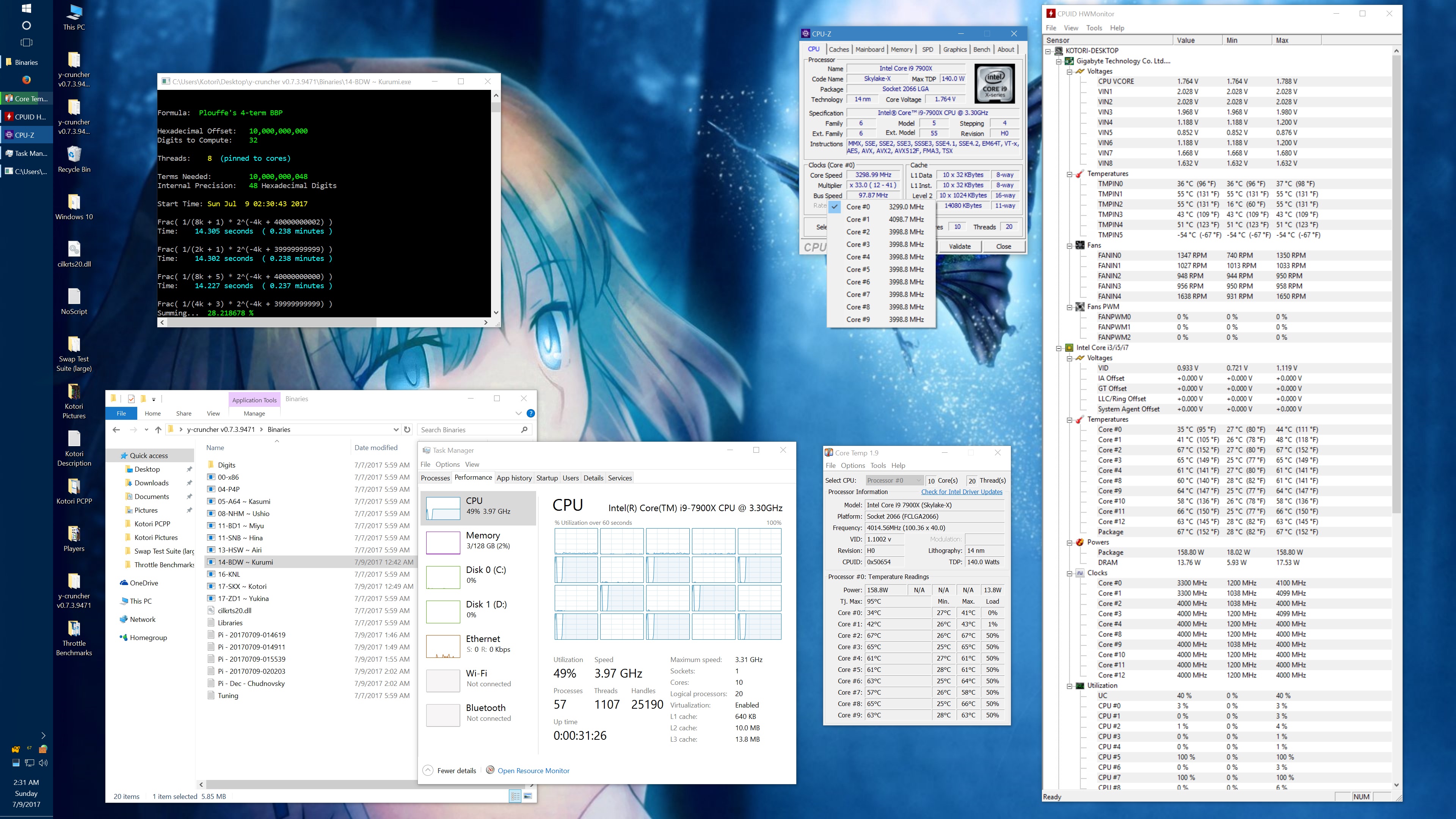
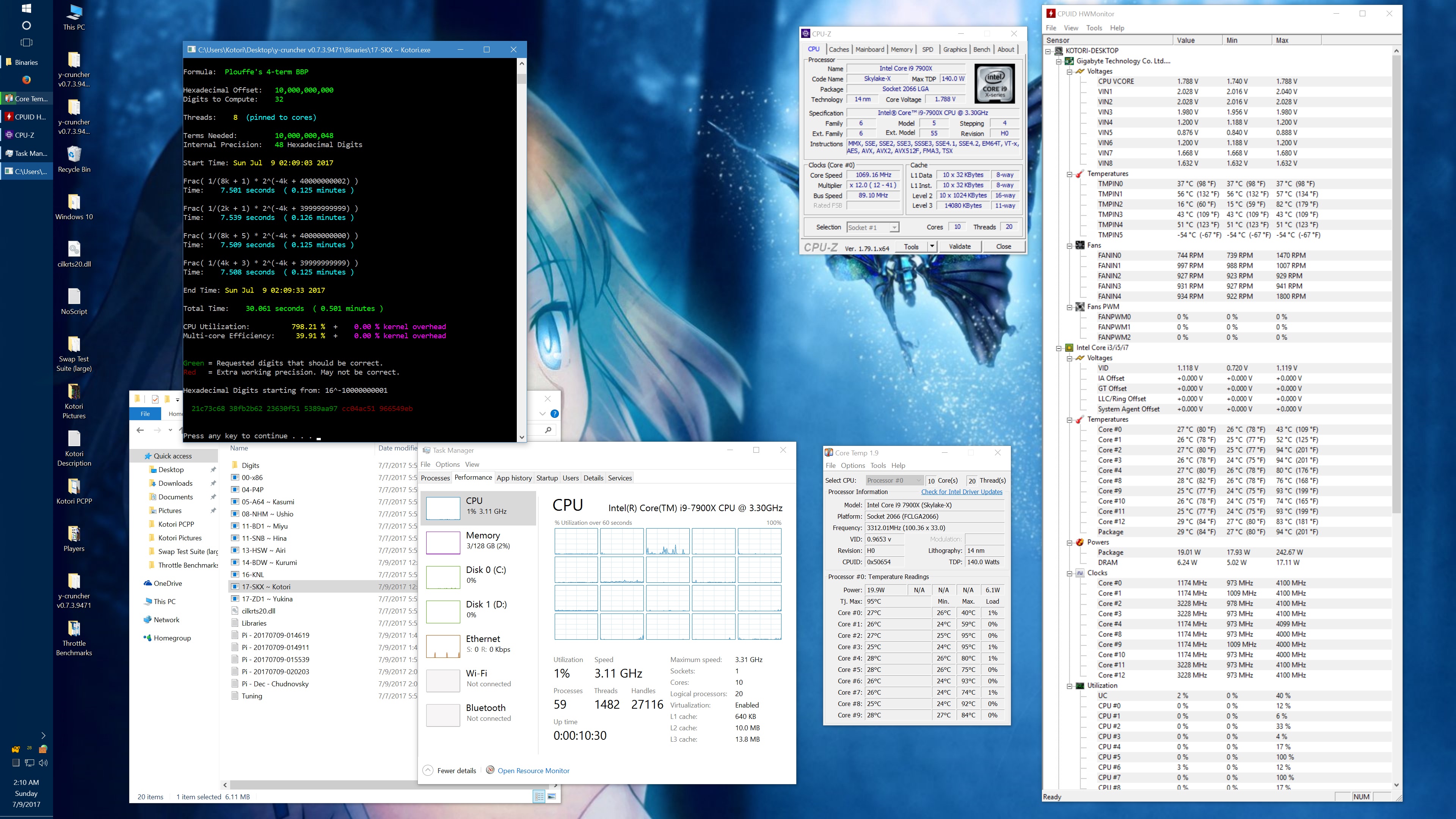
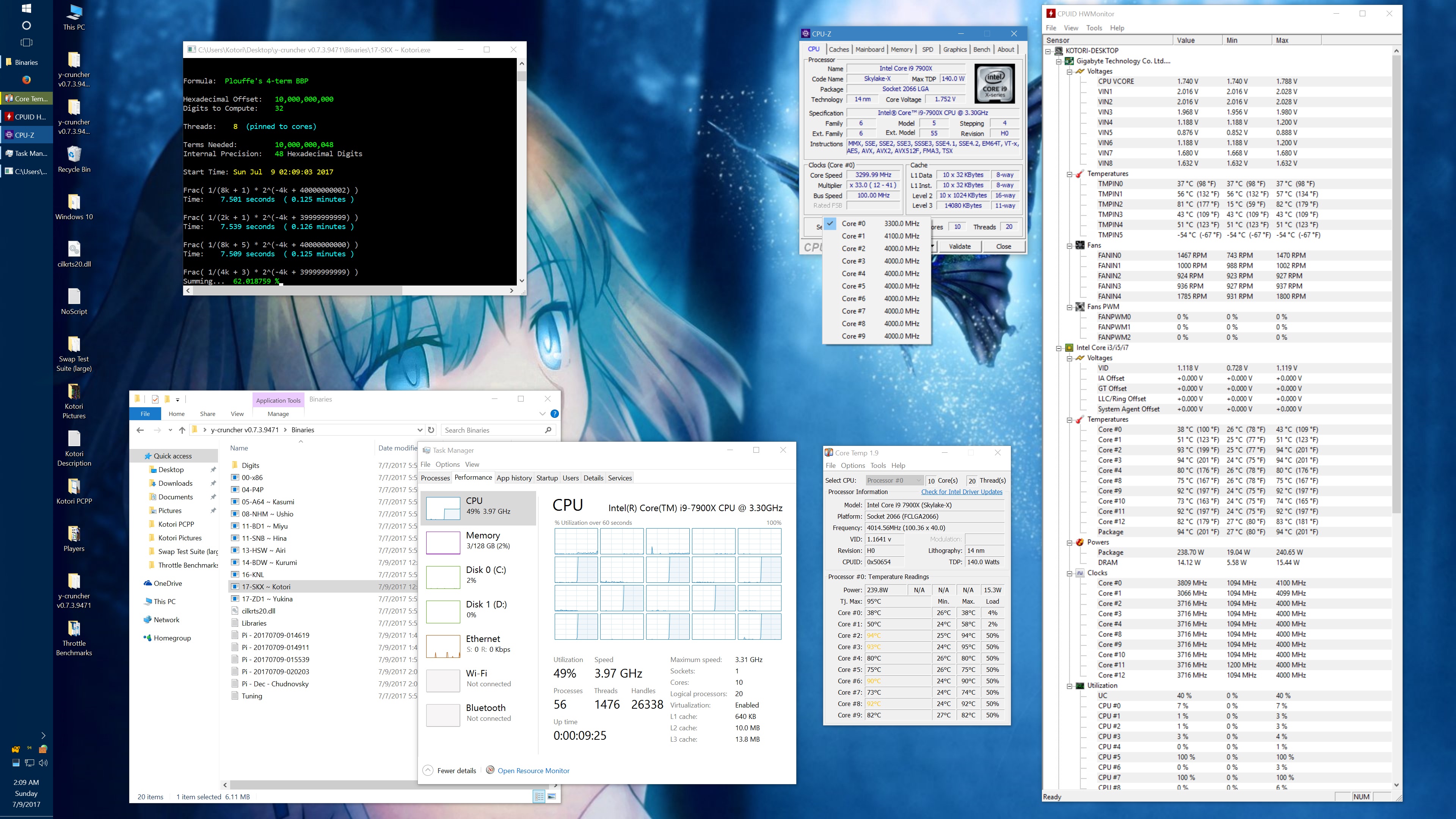
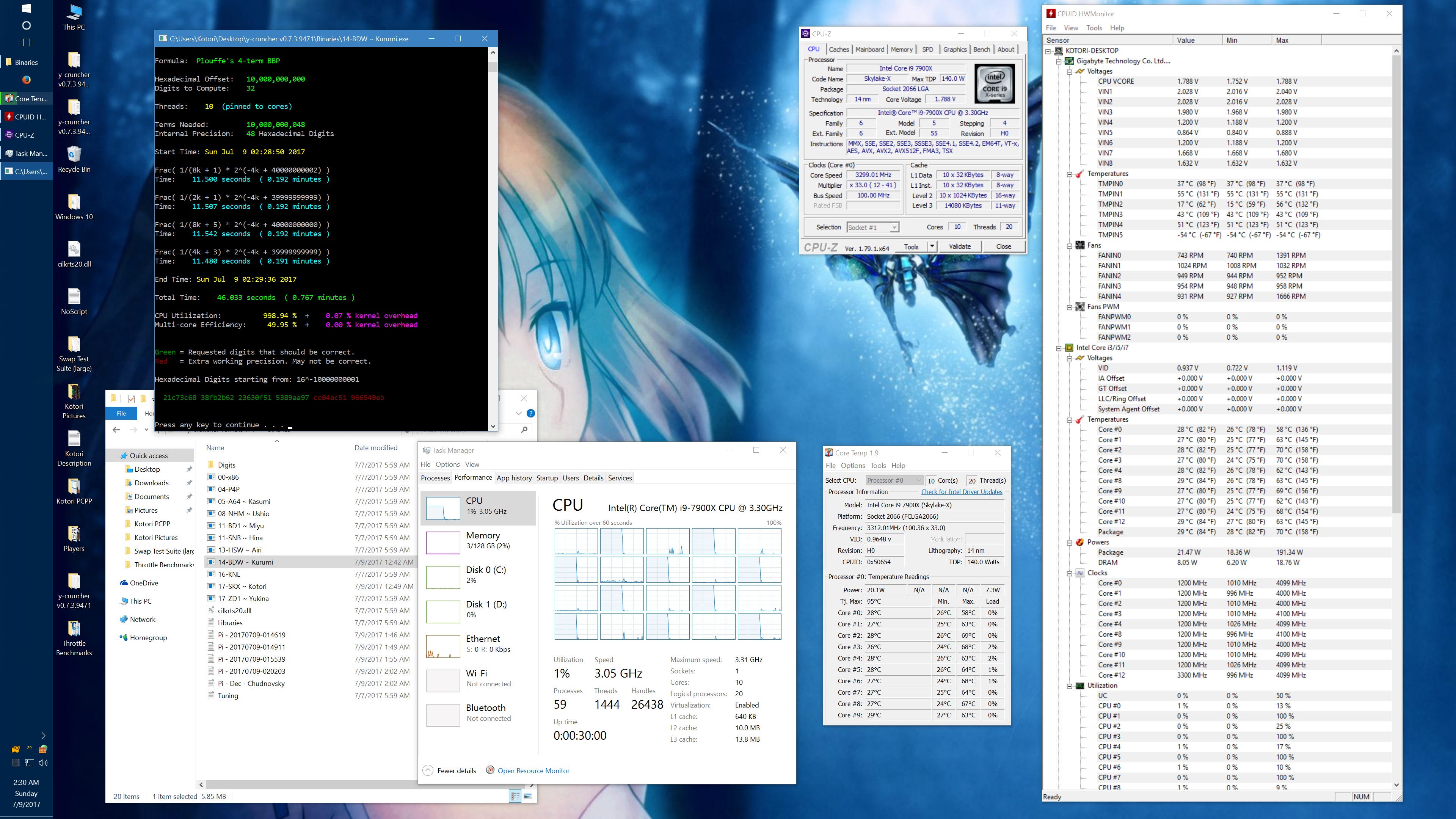
Within minutes of getting my system setup, I started noticing inconsistencies in performance. And after spending a long Friday night investigating the issue, I determined that there was a sort of "Phantom throttling" of AVX512 code when certain thermal limits are exceeded.
"Phantom throttling" is the term that I used to describe the problem in my emails with the Silicon Lottery vendor. And it looks like I'm not the only one using that term anymore. Phantom throttling is when the processor gets throttled without a change in clock frequency. For many years, processors have throttled down for many reasons to protect it from damage. But when throttling happens, it has always been done by lowering the clock frequency - which is visible in a monitor like CPUz. Skylake X is the first line of processors to break from this and it makes it more difficult to detect the throttling.
Right now, the phantom throttling phenomenon is still not well understood. Overclocker der8auer has mentioned that it could be caused by CPUz not reacting fast enough to actual clock frequency changes. On the other hand, the tests that Silicon Lottery and myself have done seem to show the that there really is no drop in clock frequency at all.
Initially, I observed this effect only with AVX512 code and thus hypothesized that the mechanism behind the throttling is the shutdown of the dedicated 512-bit FMA. But others have found that phantom throttling also occurs on AVX and scalar code as well. In short, much more investigation is needed. The lack of AVX512 programs out there certainly doesn't help and is partially why I'm rushing this release of y-cruncher v0.7.3.
Currently, there are no known reliable ways of stopping the throttling and results vary heavily by motherboard manufacturer. But maxing out thermal limits and disabling all thermal protections seems to help. (Don't try this at home if you don't know what you're doing or you aren't at least moderately experienced in overclocking. You can destroy your processor and/or motherboard if you aren't careful.)
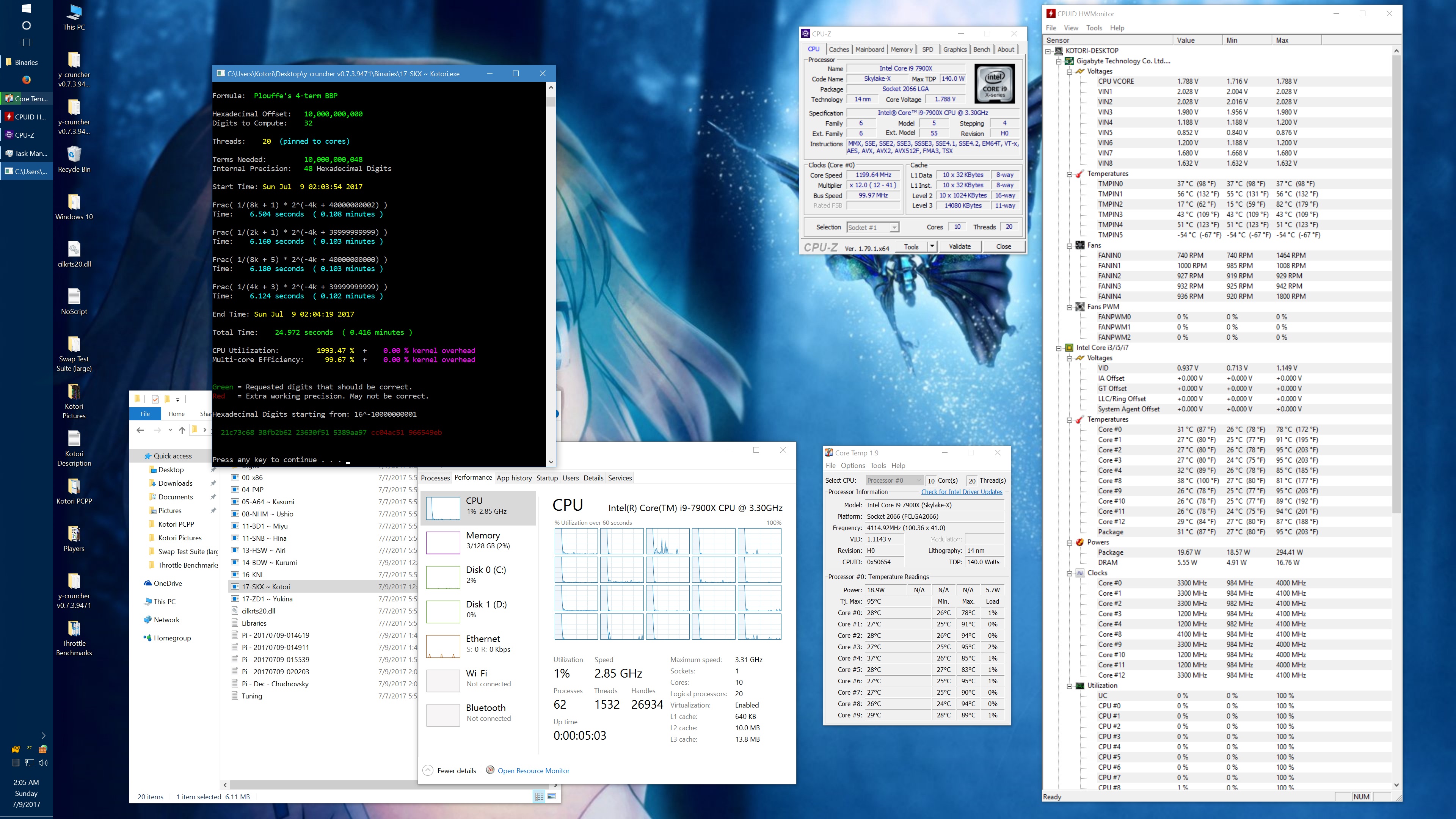
Update (July 9, 2017):
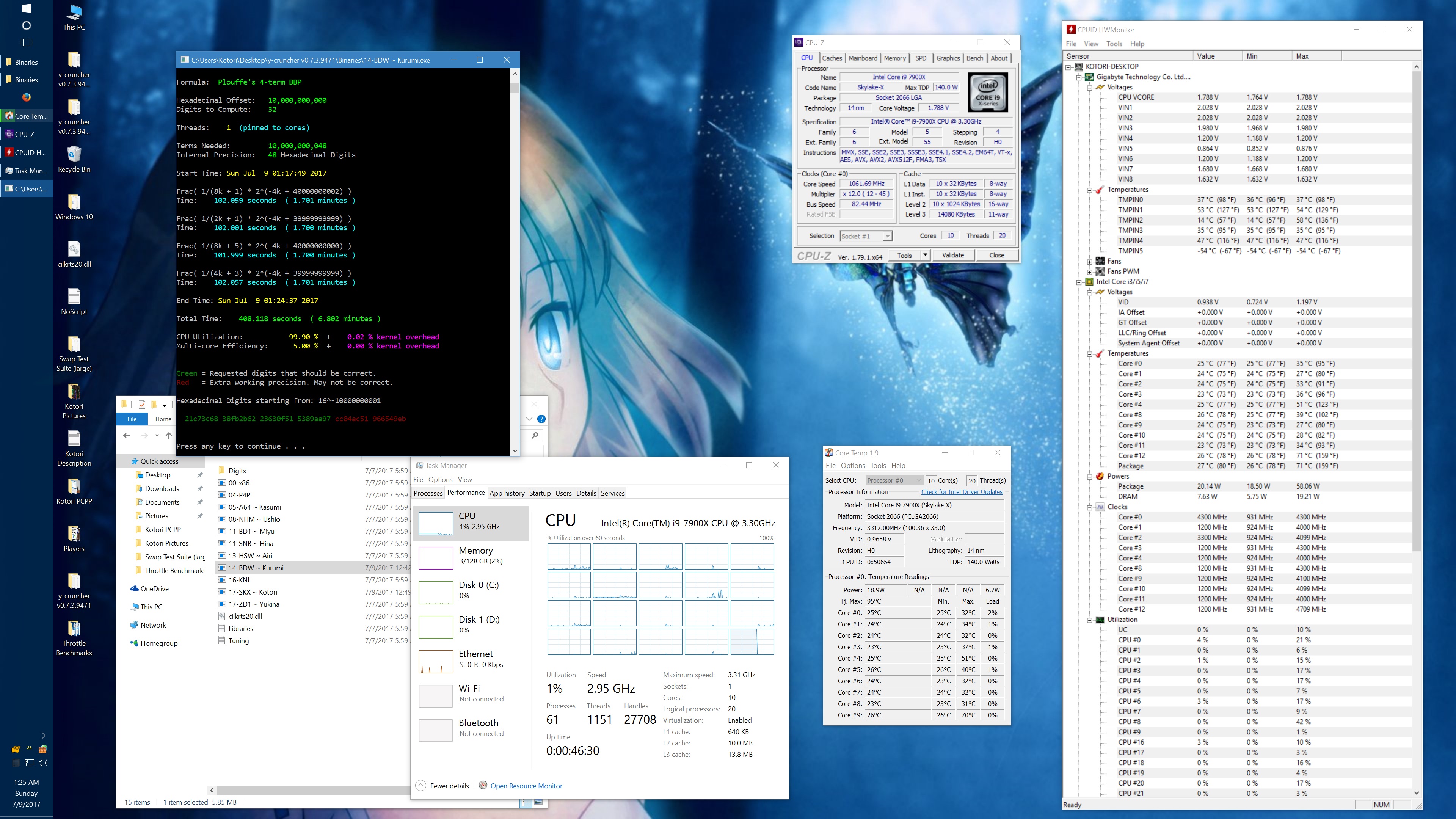
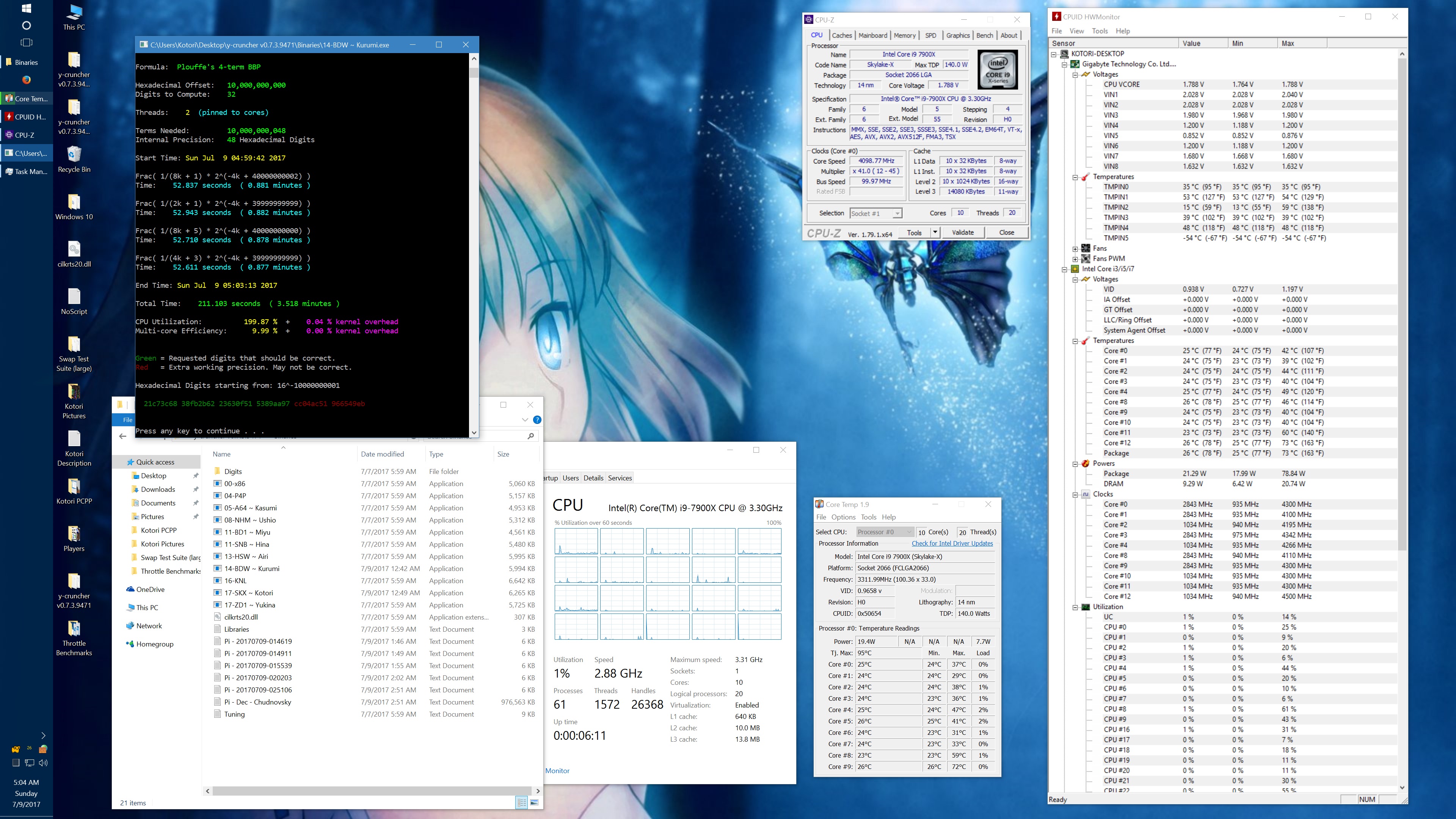
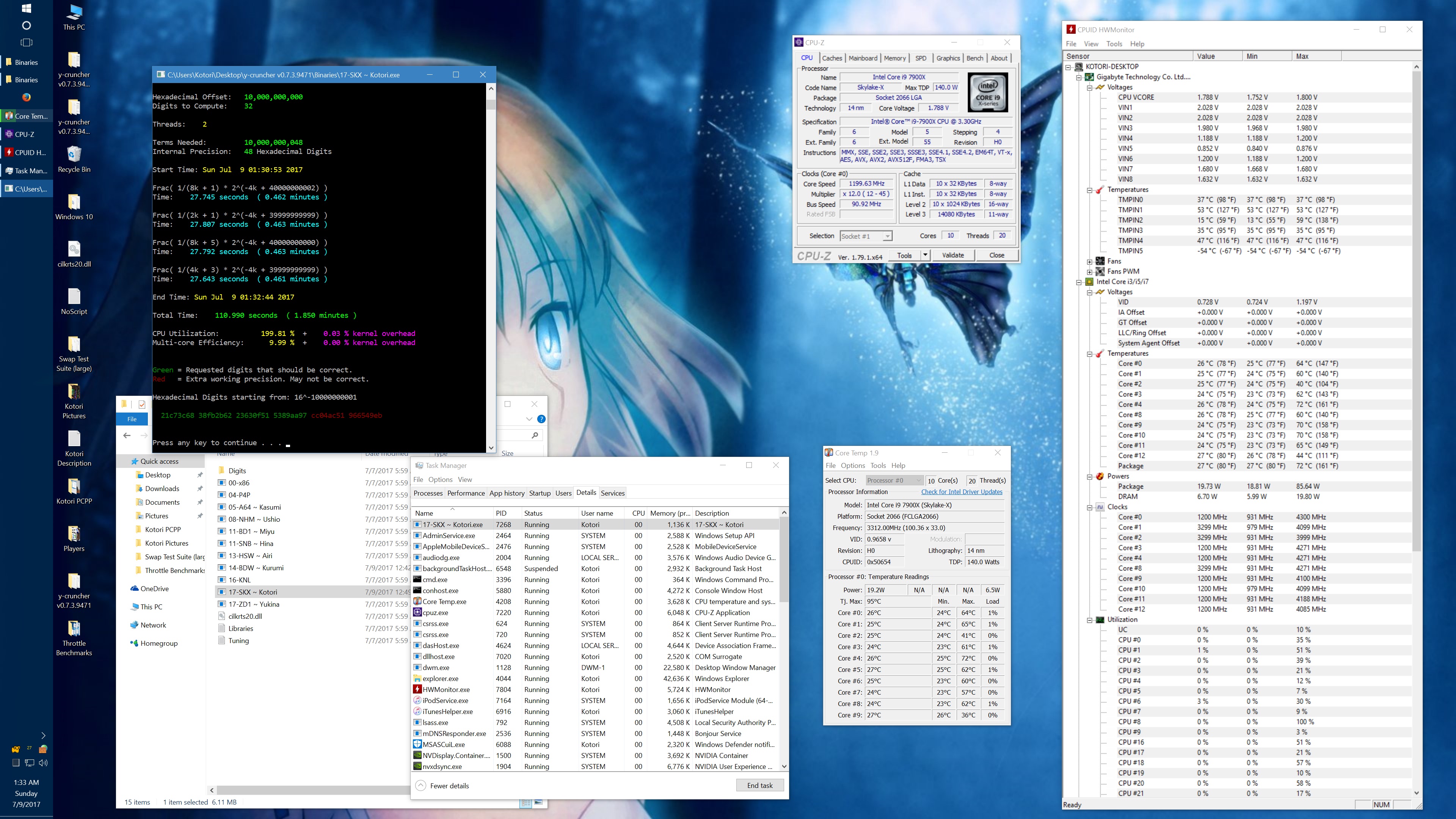
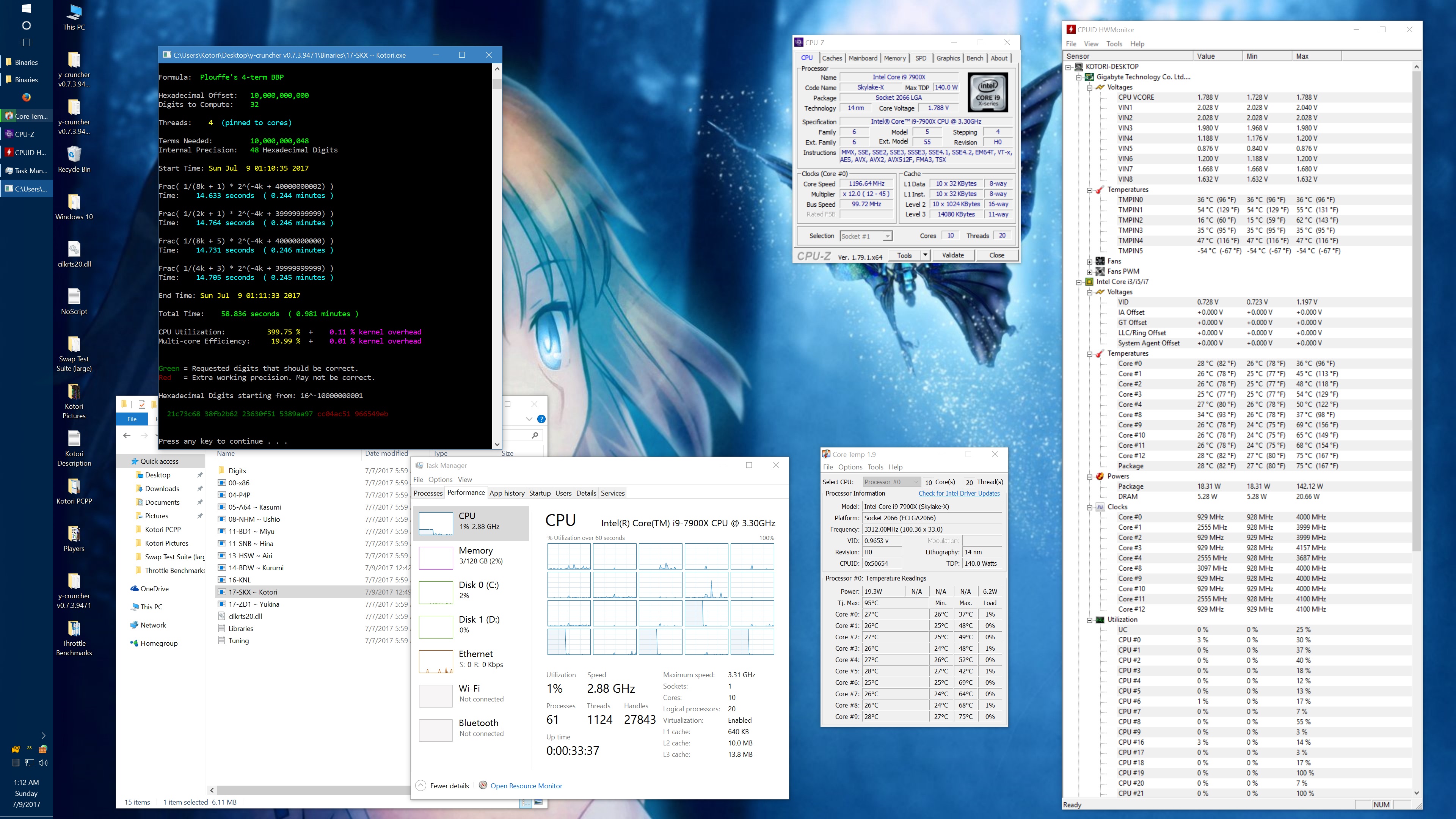
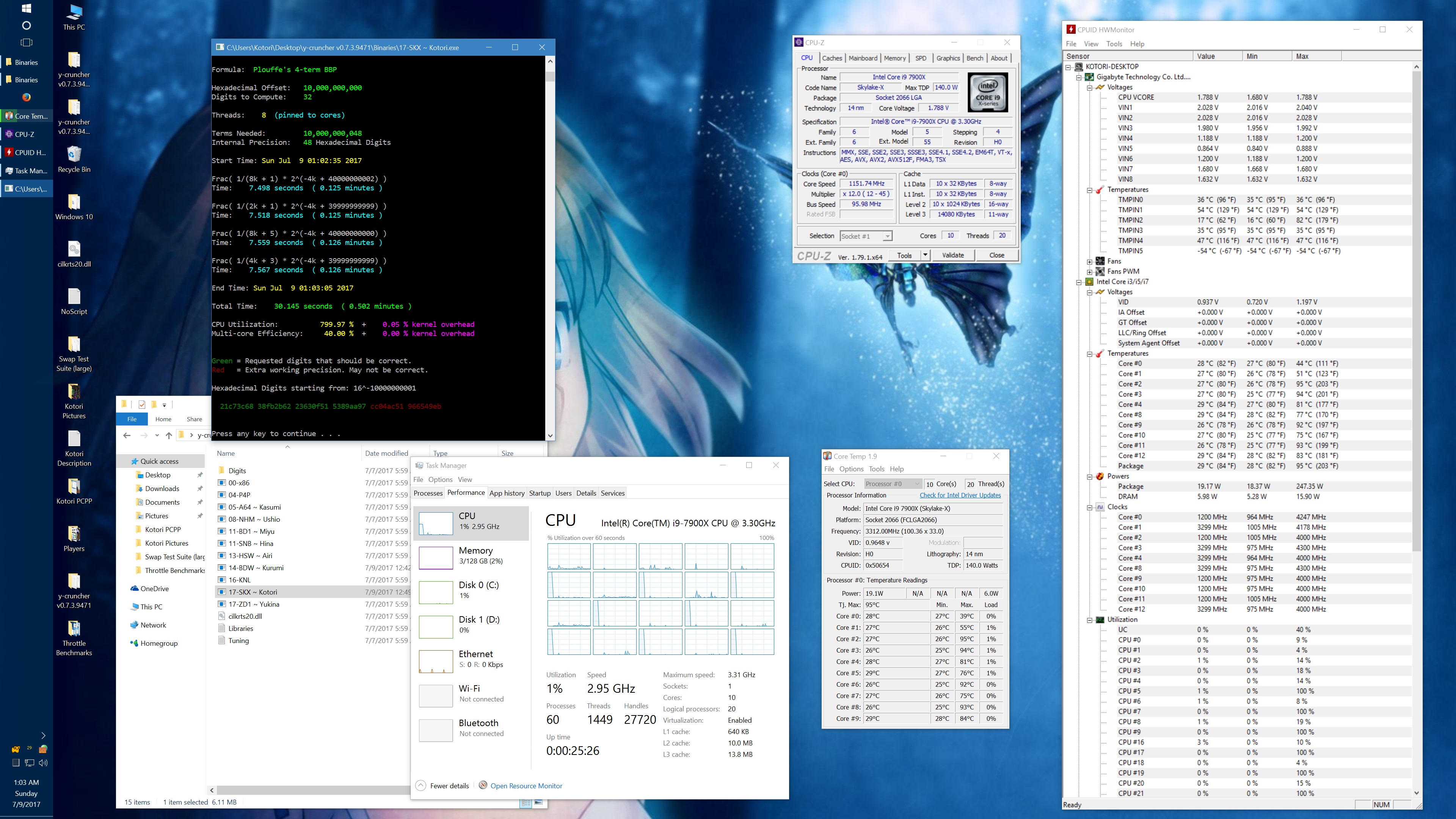
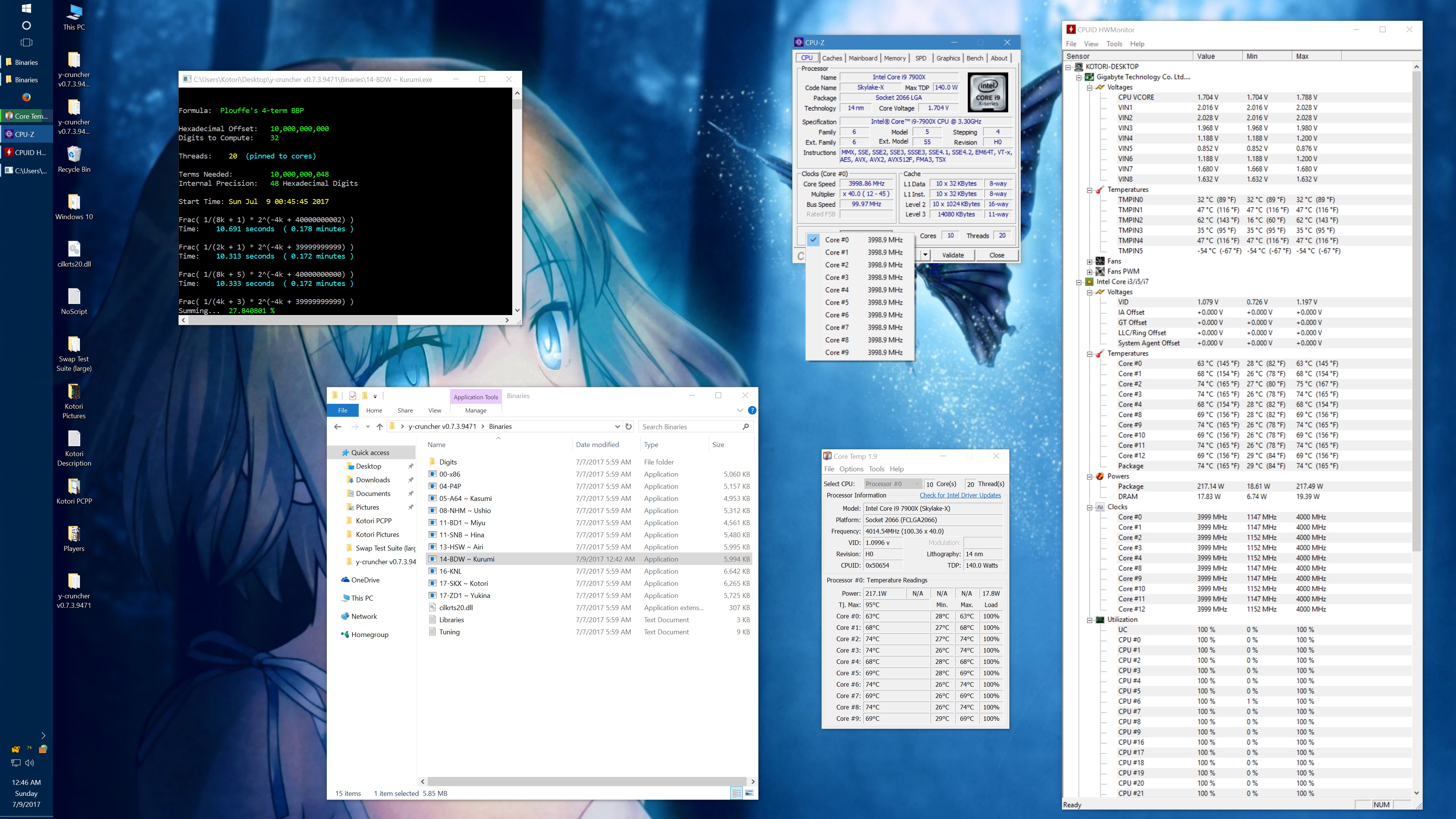
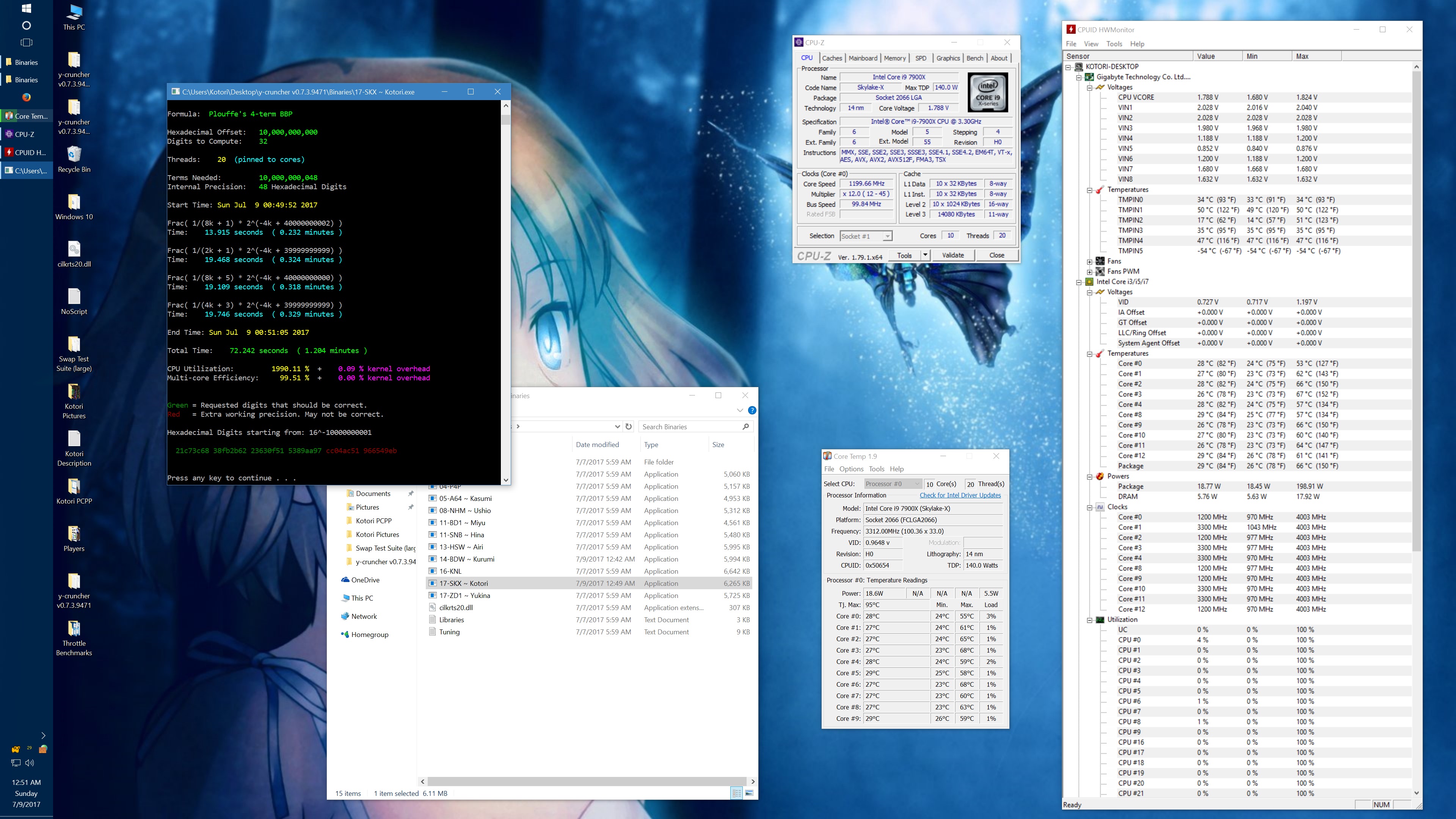
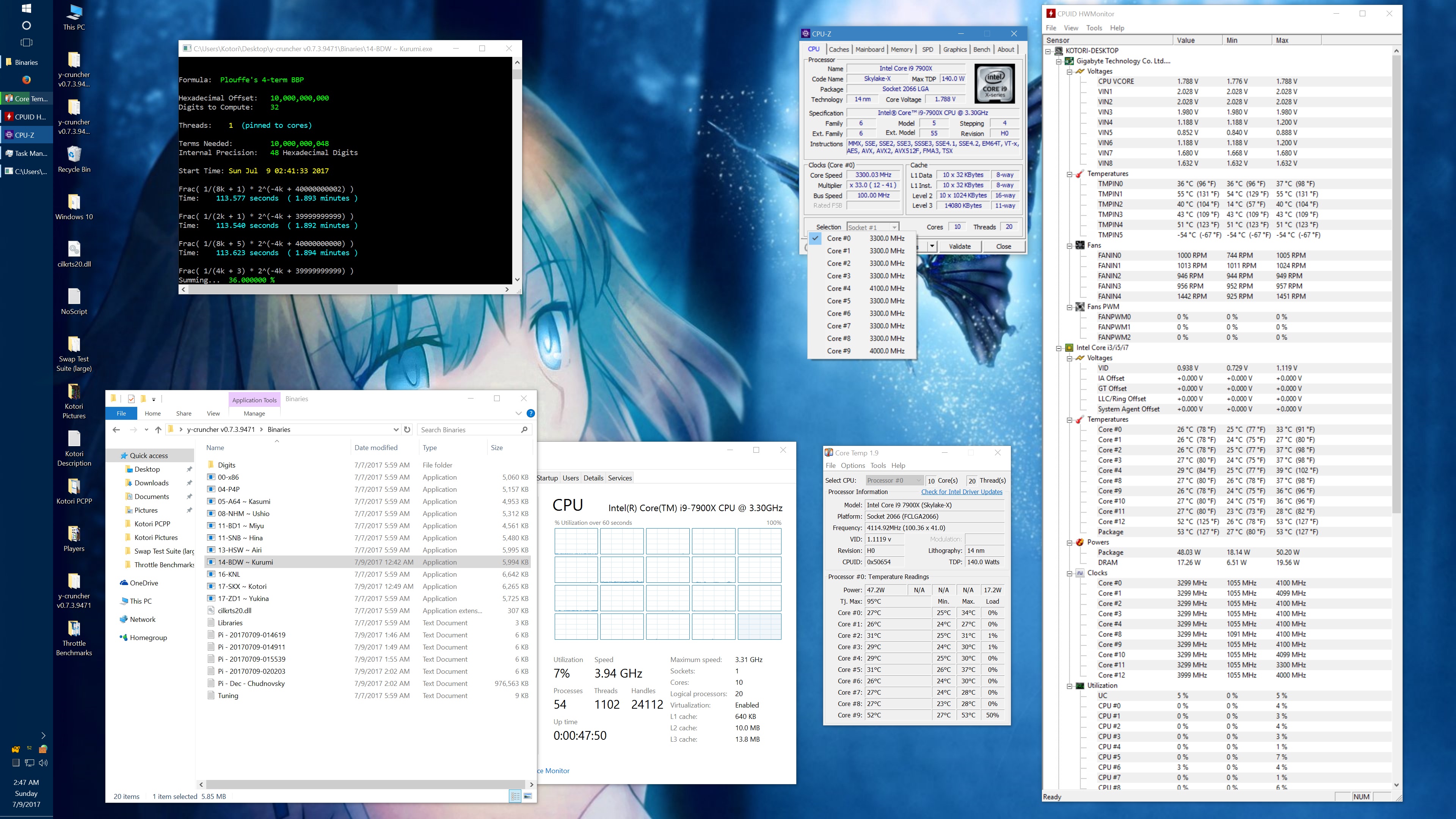
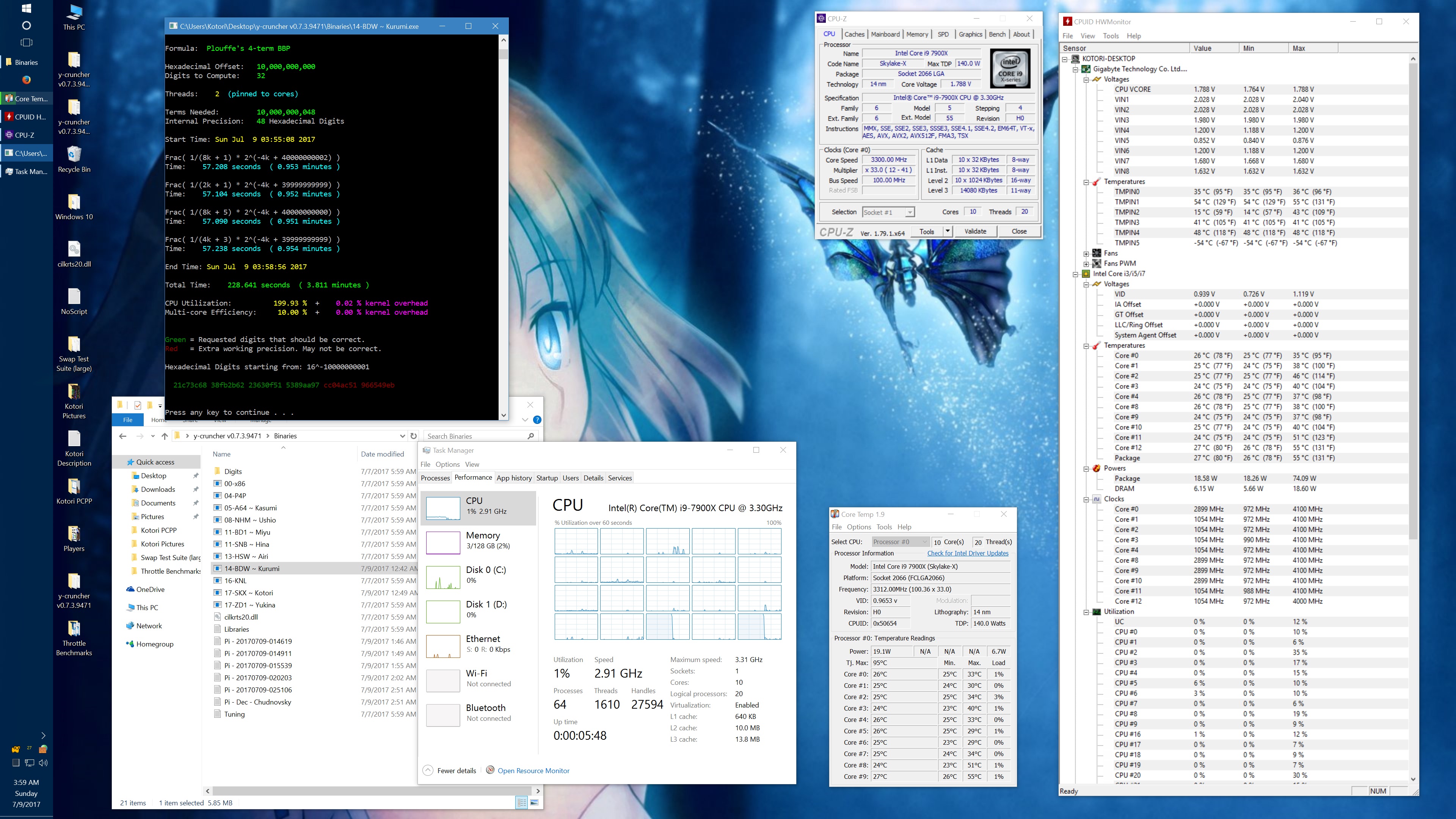
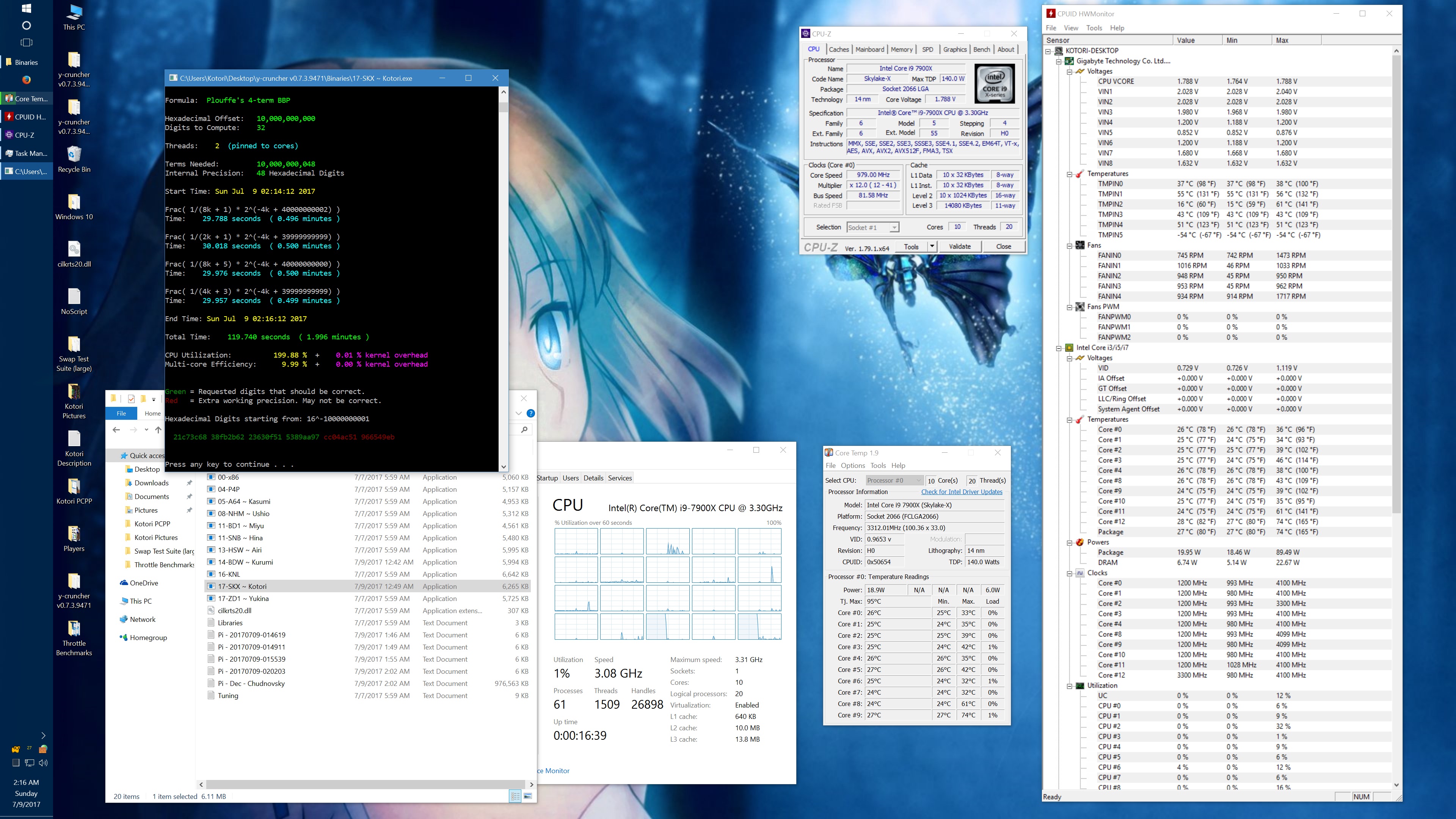
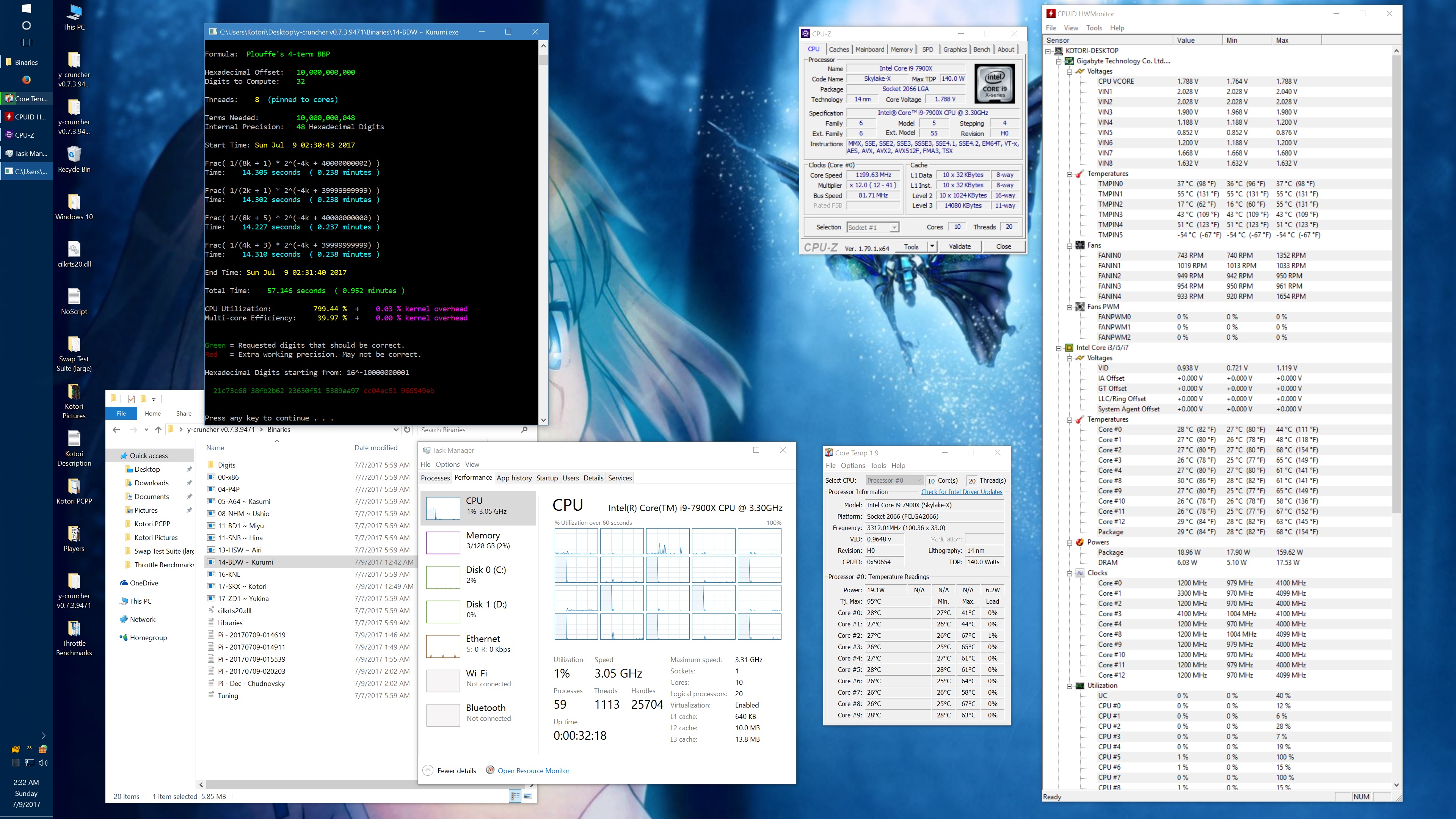
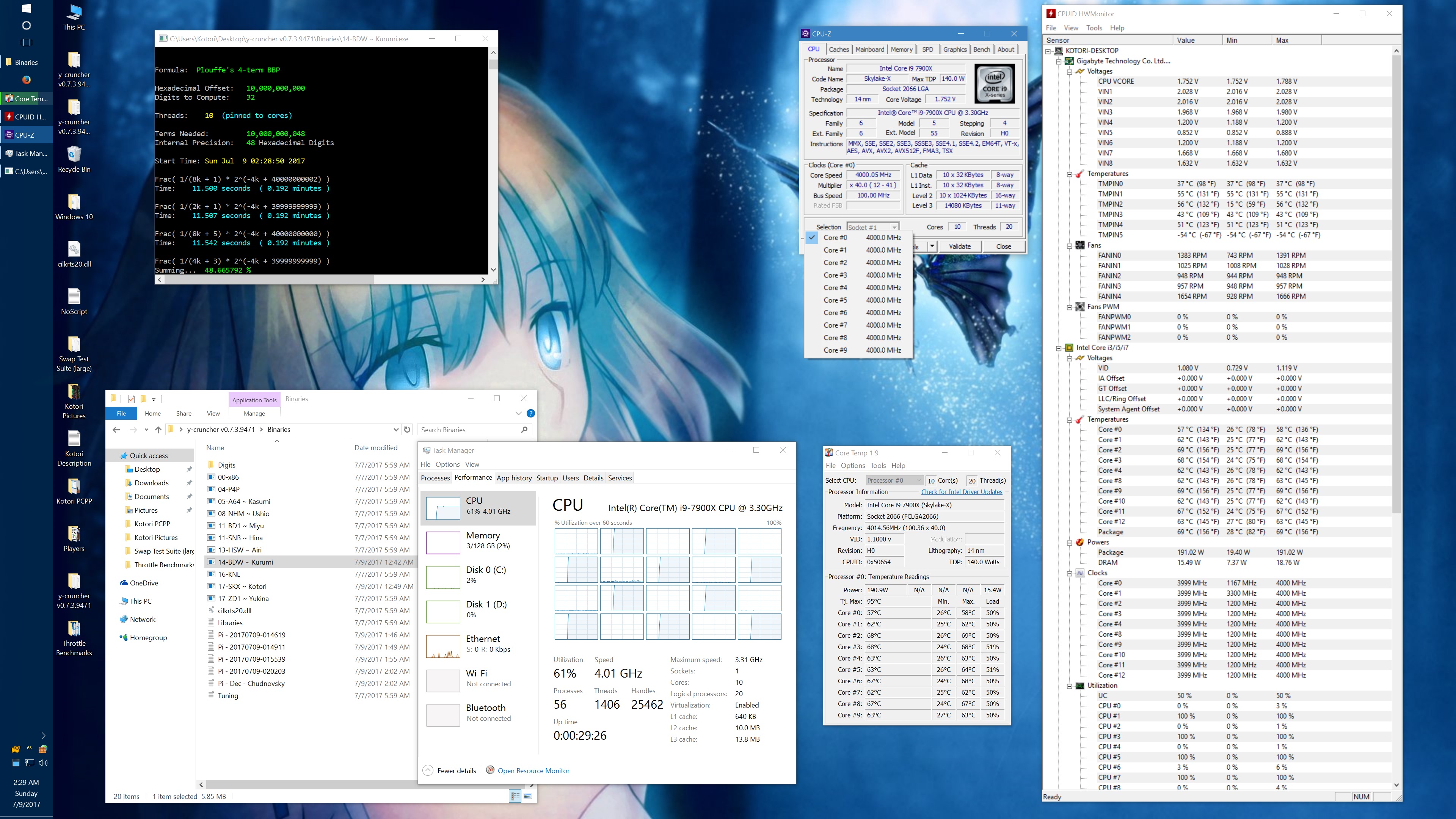
I got asked about this, so here's some data showing the phantom throttling at stock settings. The pink entries are the ones with phantom throttling.
10 billion Hex-Digit of Pi - Plouffe's 4-term BBP Formula (y-cruncher v0.7.3) Core i9 7900X - Gigabyte AORUS Gaming 7 (BIOS F7a) |
||||||||
All Stock Settings |
||||||||
| Binary: | AVX2 (14-BDW) | AVX512 (17-SKX) | ||||||
| Threads/Cores | Time (secs) | Clock Speed | Power | Max Temperature | Time (secs) | Clock Speed | Power | Max Temperature |
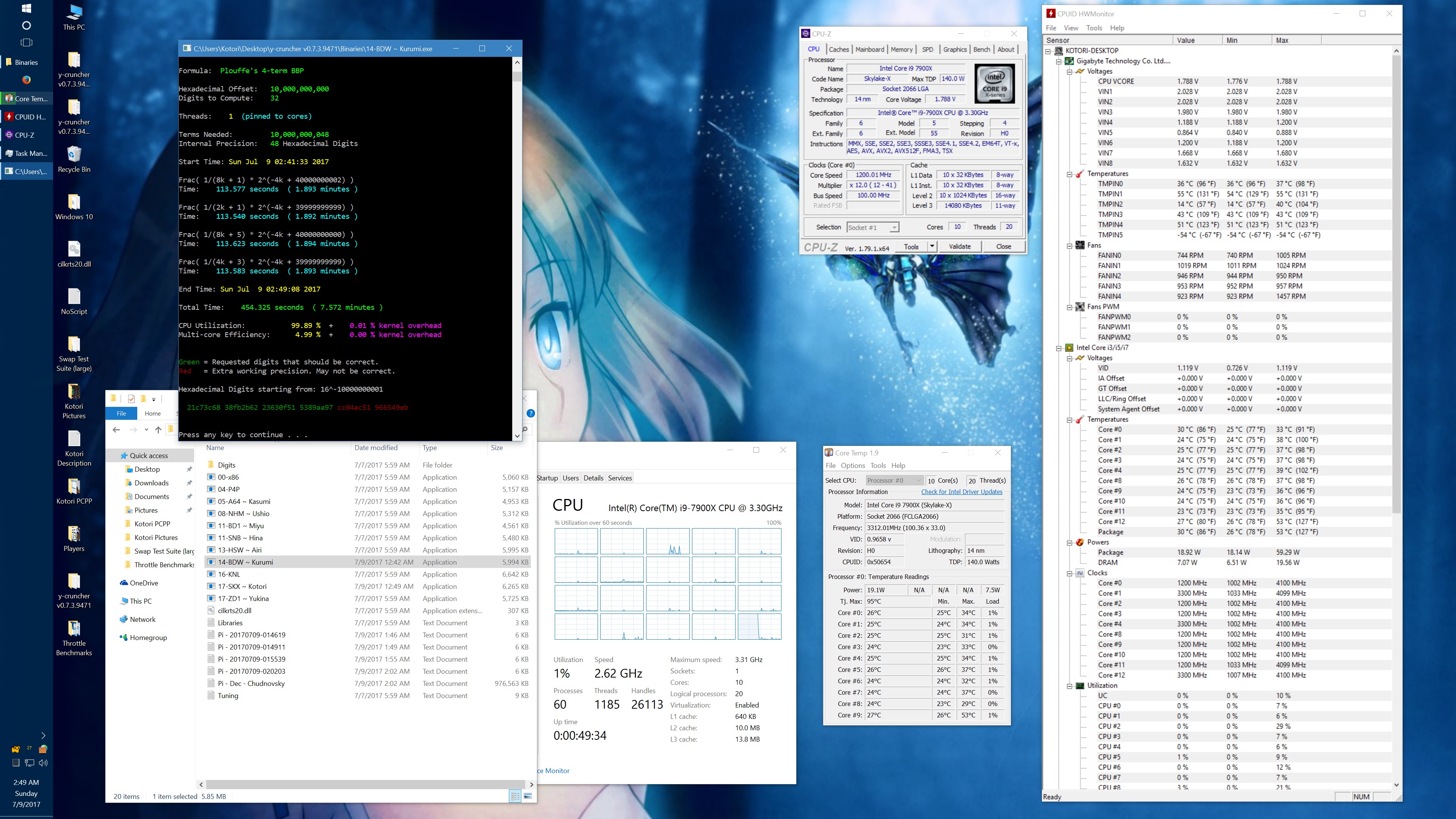
| 1 thread/1 core | 408.118 | 4.5 GHz | 58 W | 70°C | 215.399 | 4.5 GHz | 62 W | 71°C |
| 2 threads/2 cores | 211.103 | 4.0 - 4.1 GHz | 77 W | 72°C | 110.990 | 4.1 GHz | 87 W | 74°C |
| 4 threads/4 cores | 111.948 | 4.0 GHz | 99 W | 61°C | 58.836 | 4.0 GHz | 136 W | 74°C |
| 8 threads/8 cores | 57.189 | 4.0 GHz | 160 W | 67°C | 30.145 | 4.0 GHz | 244 W | 94°C |
| 10 threads/10 cores | 45.957 | 4.0 GHz | 194 W | 69°C | 51.879 | 4.0 GHz | 188 W | 68°C |
| 20 threads/10 cores | 41.669 | 4.0 GHz | 217 W | 74°C | 72.242 | 4.0 GHz | 160 W | 68°C |
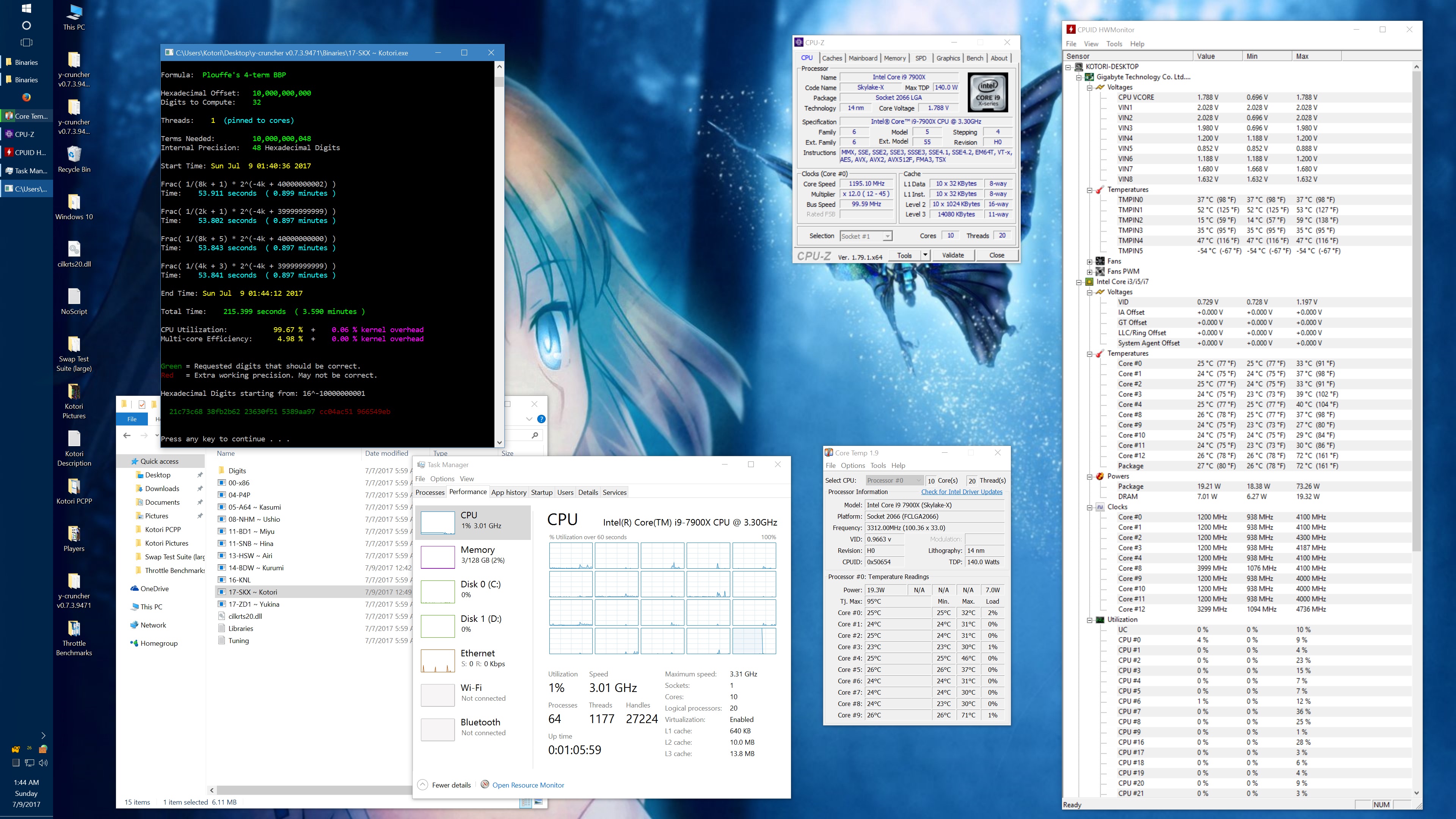
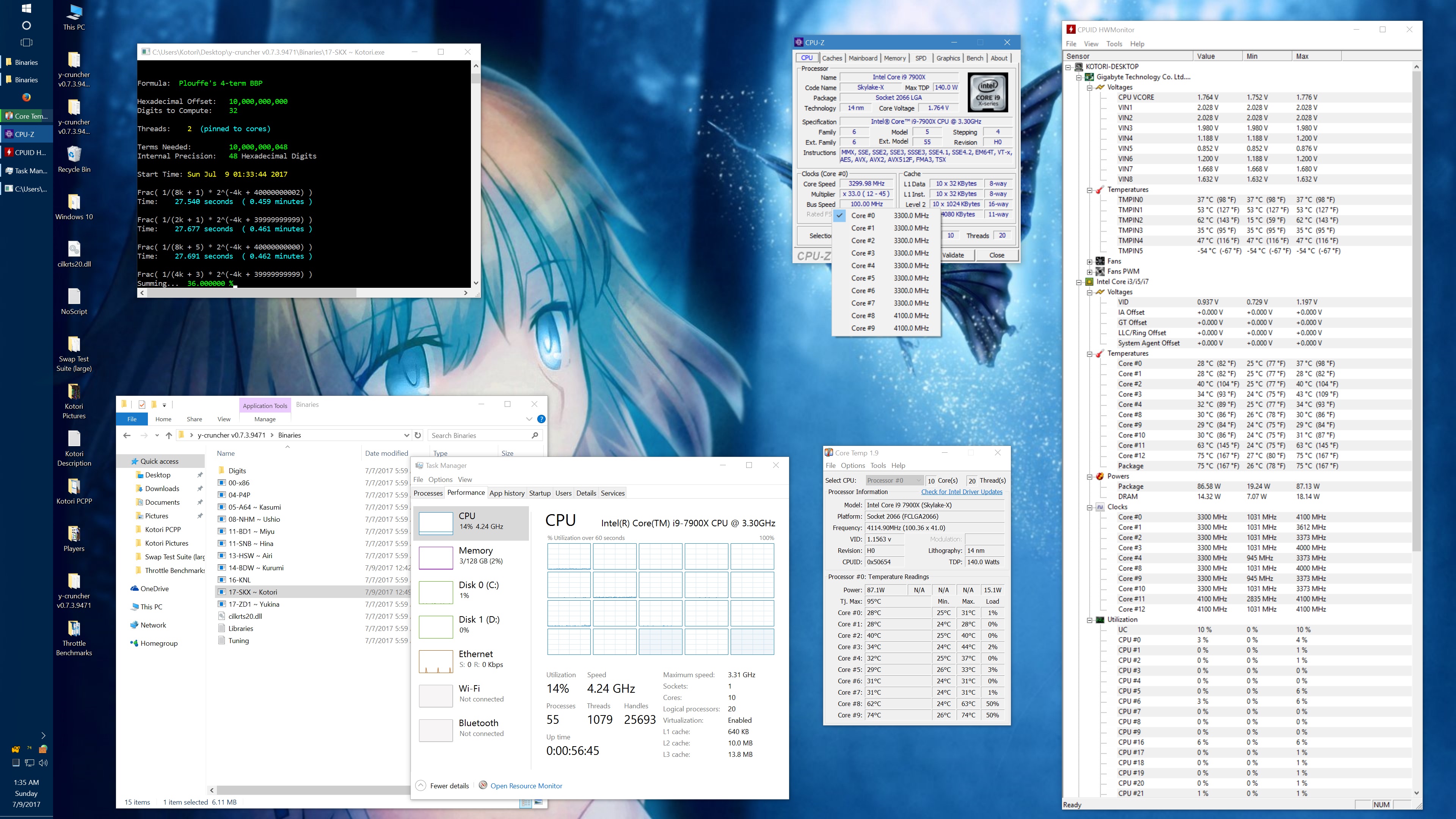
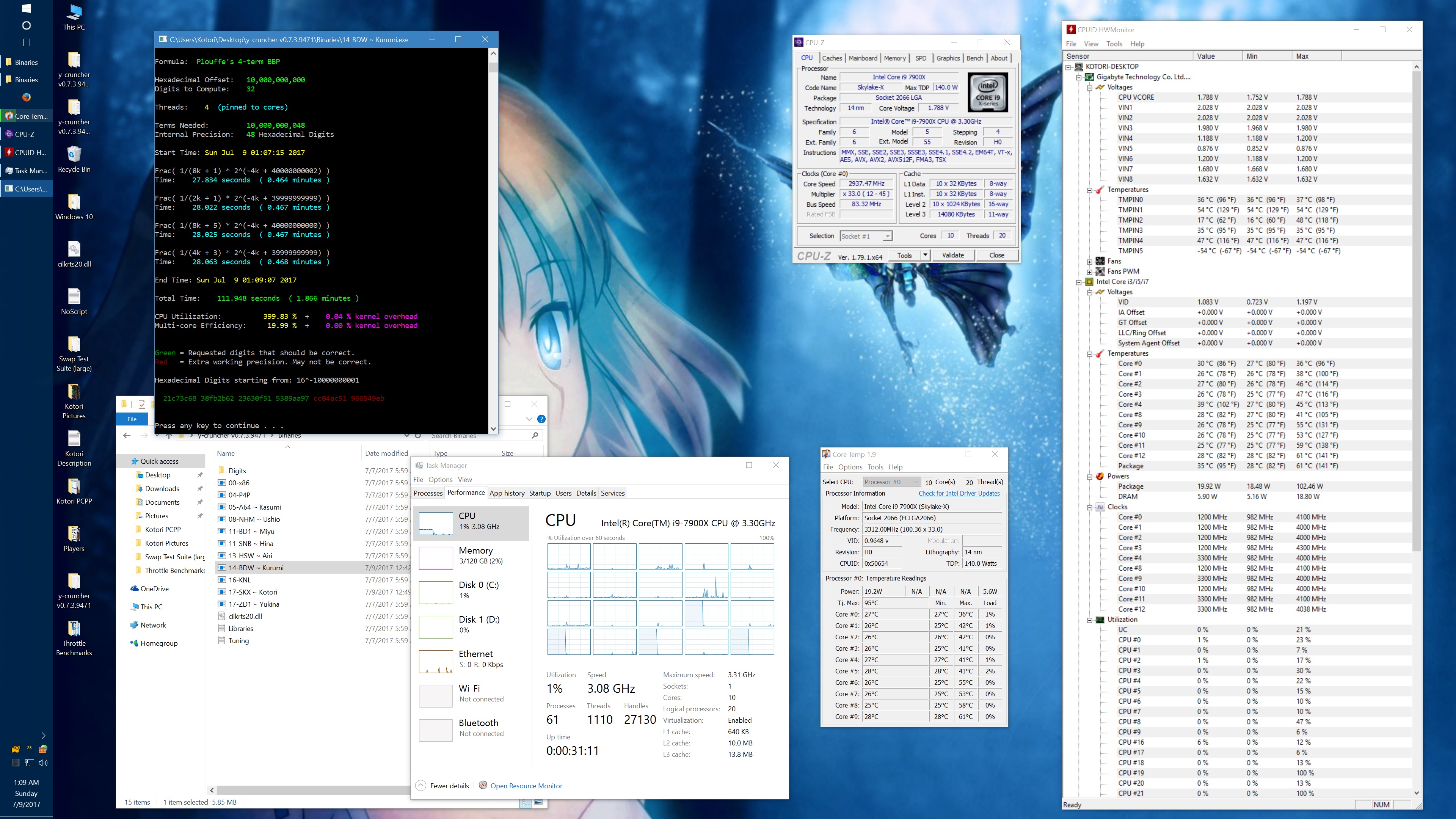
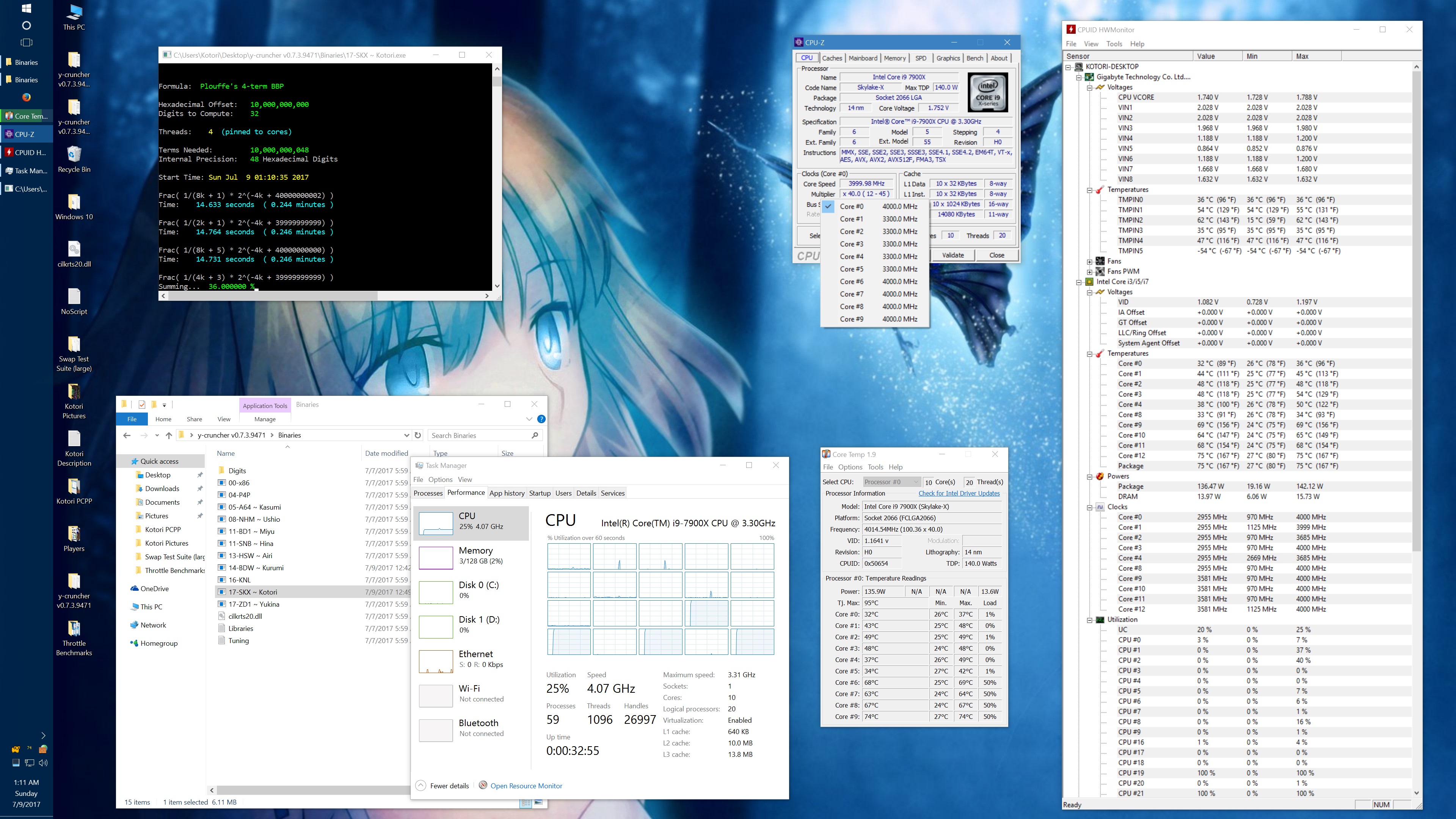
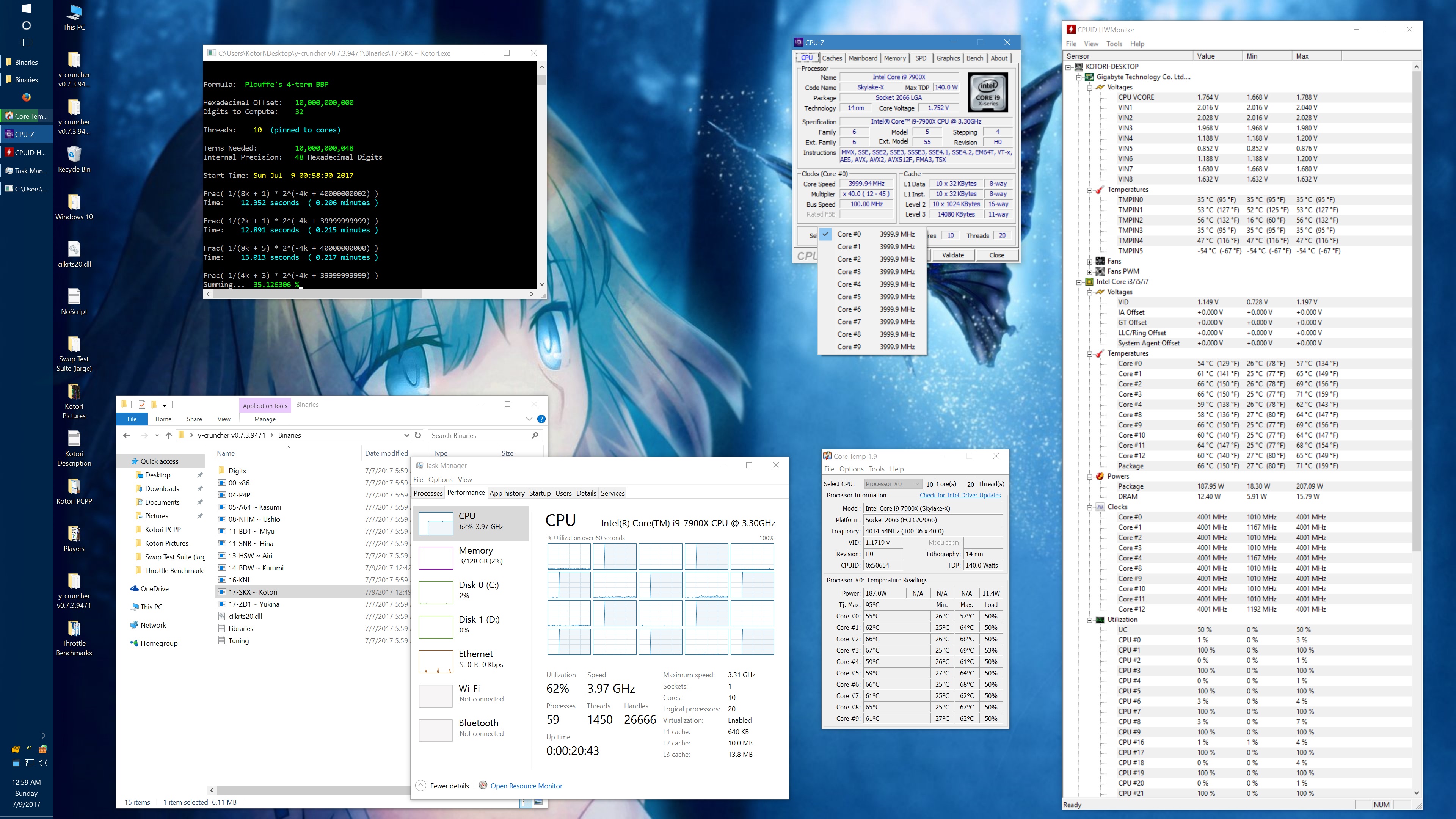
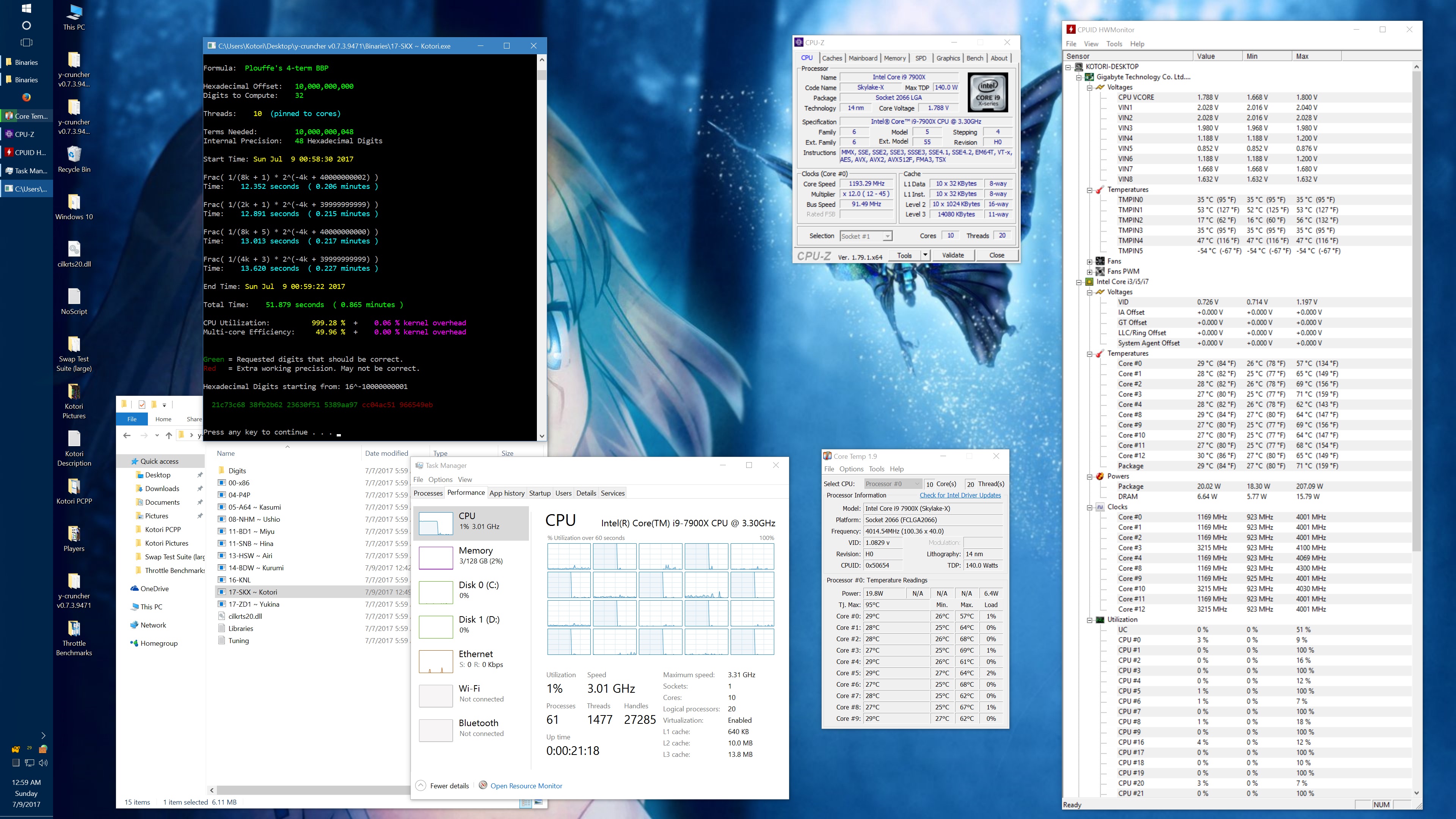
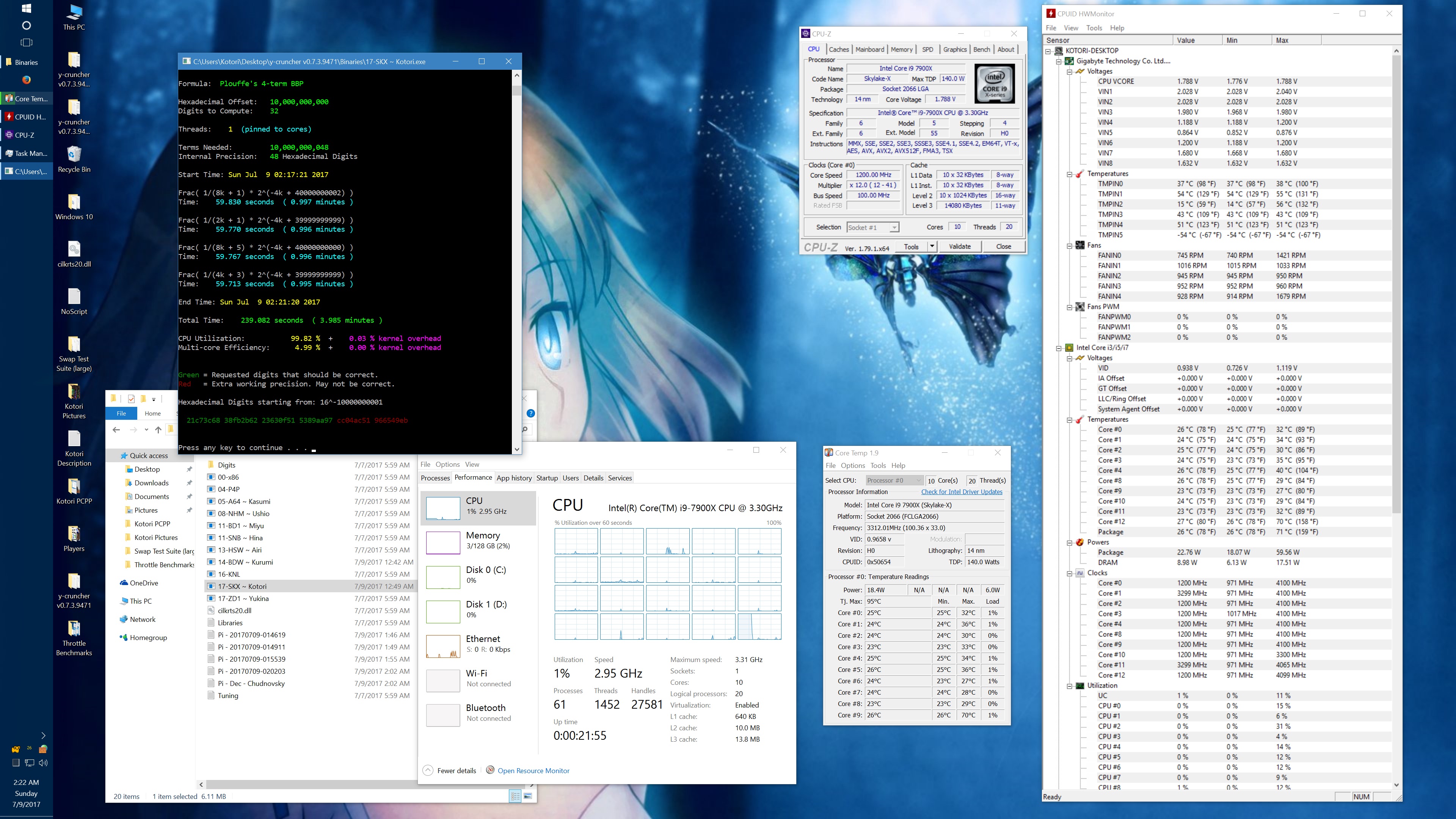
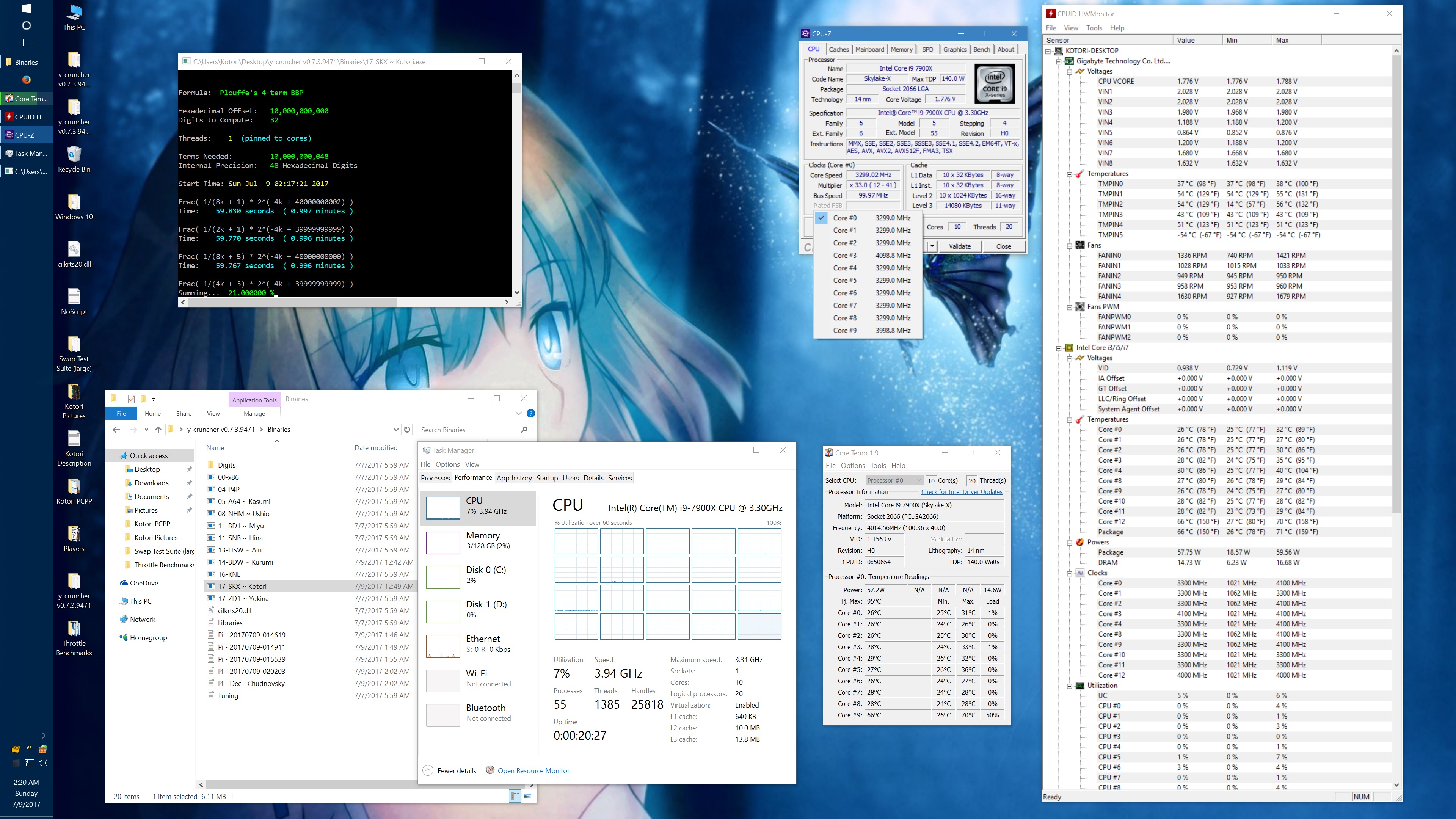
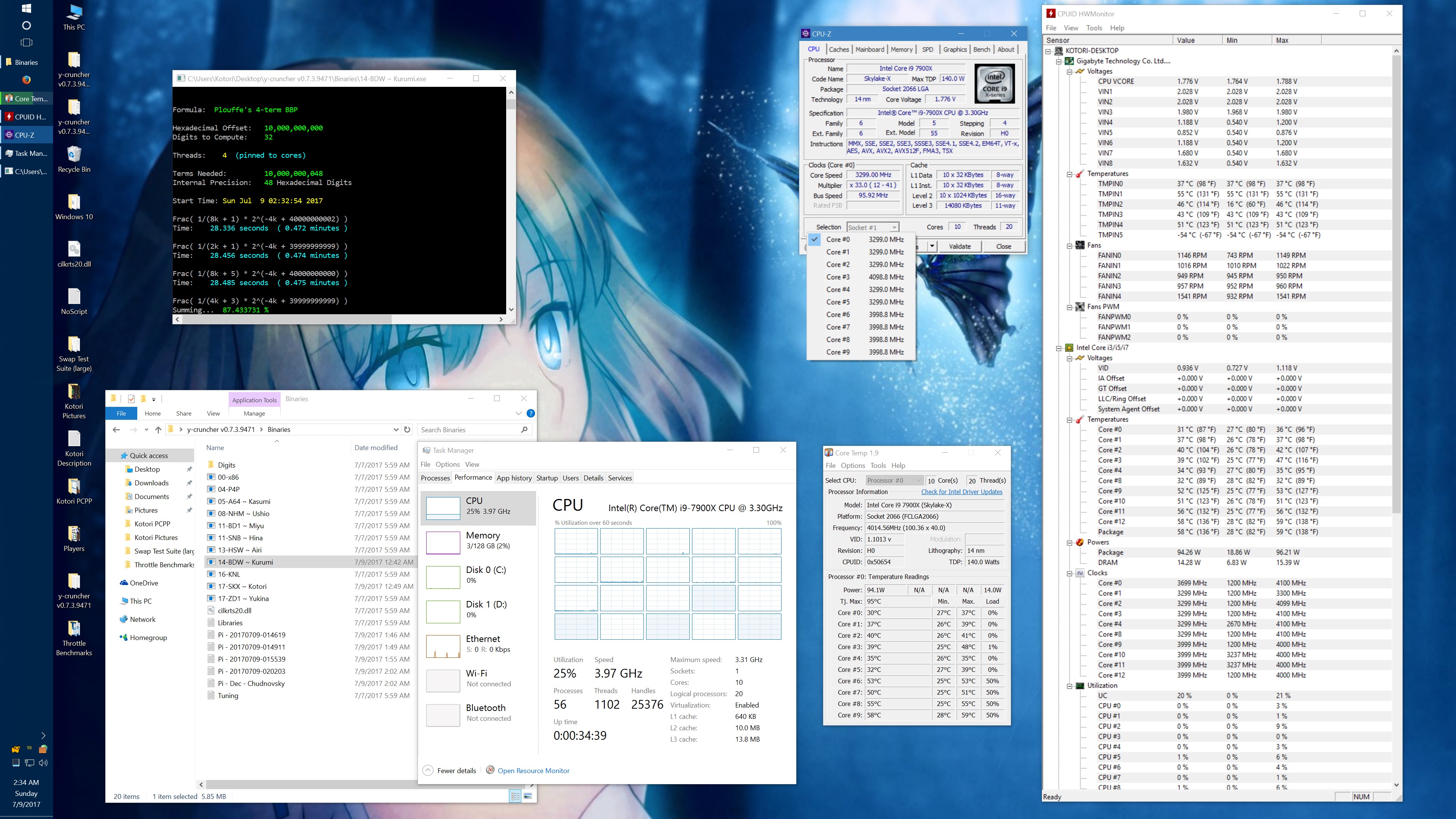
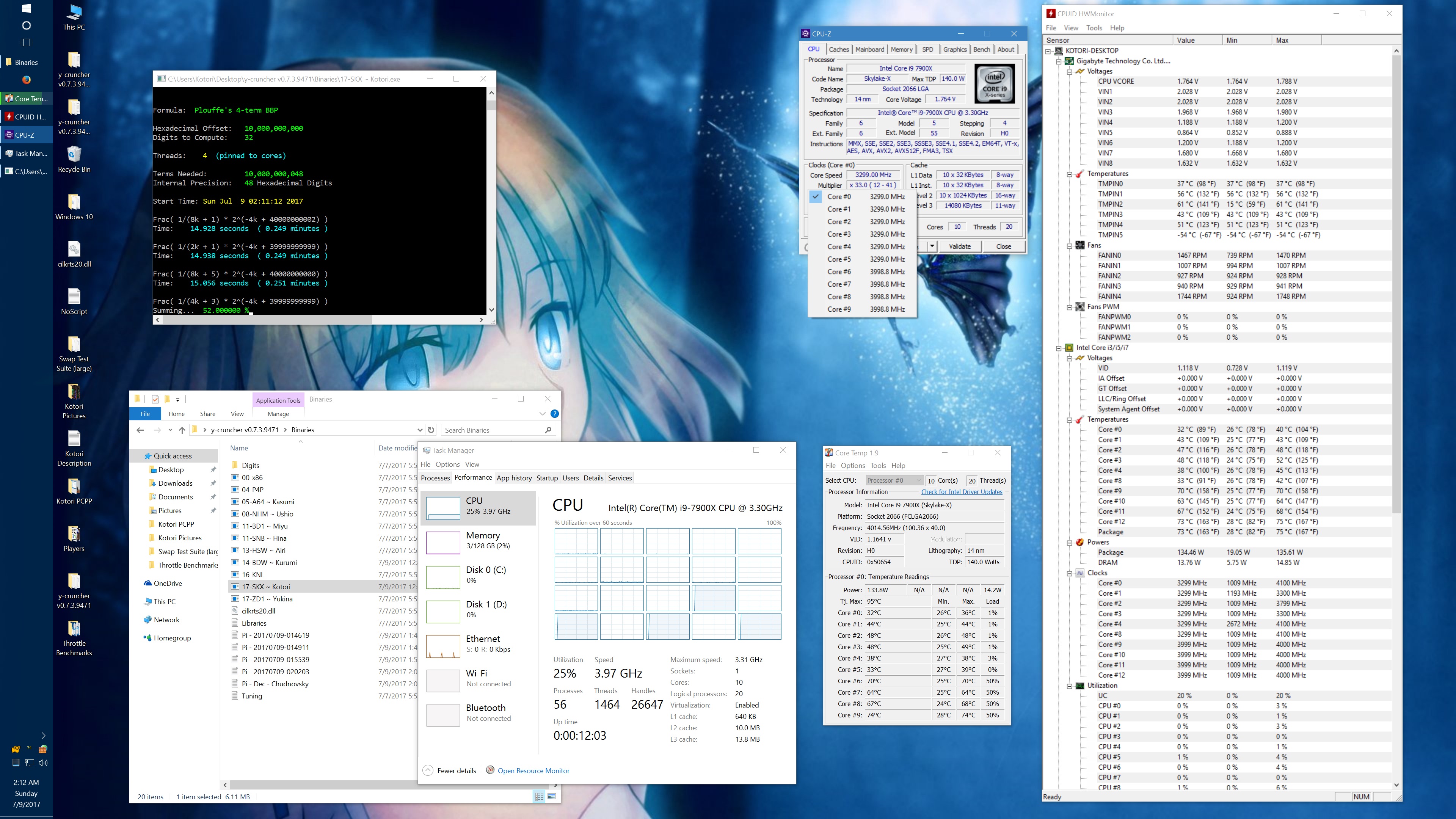
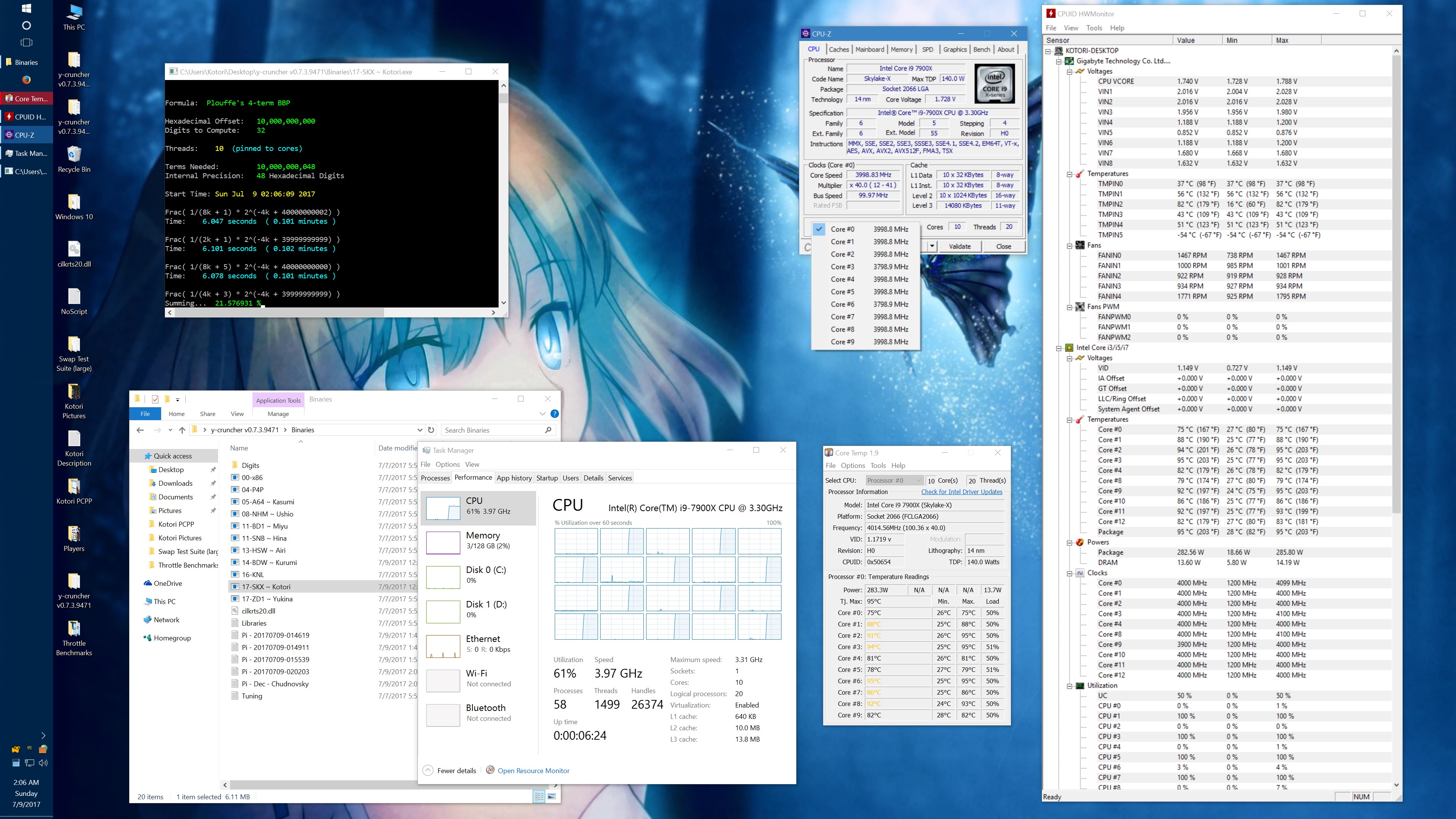
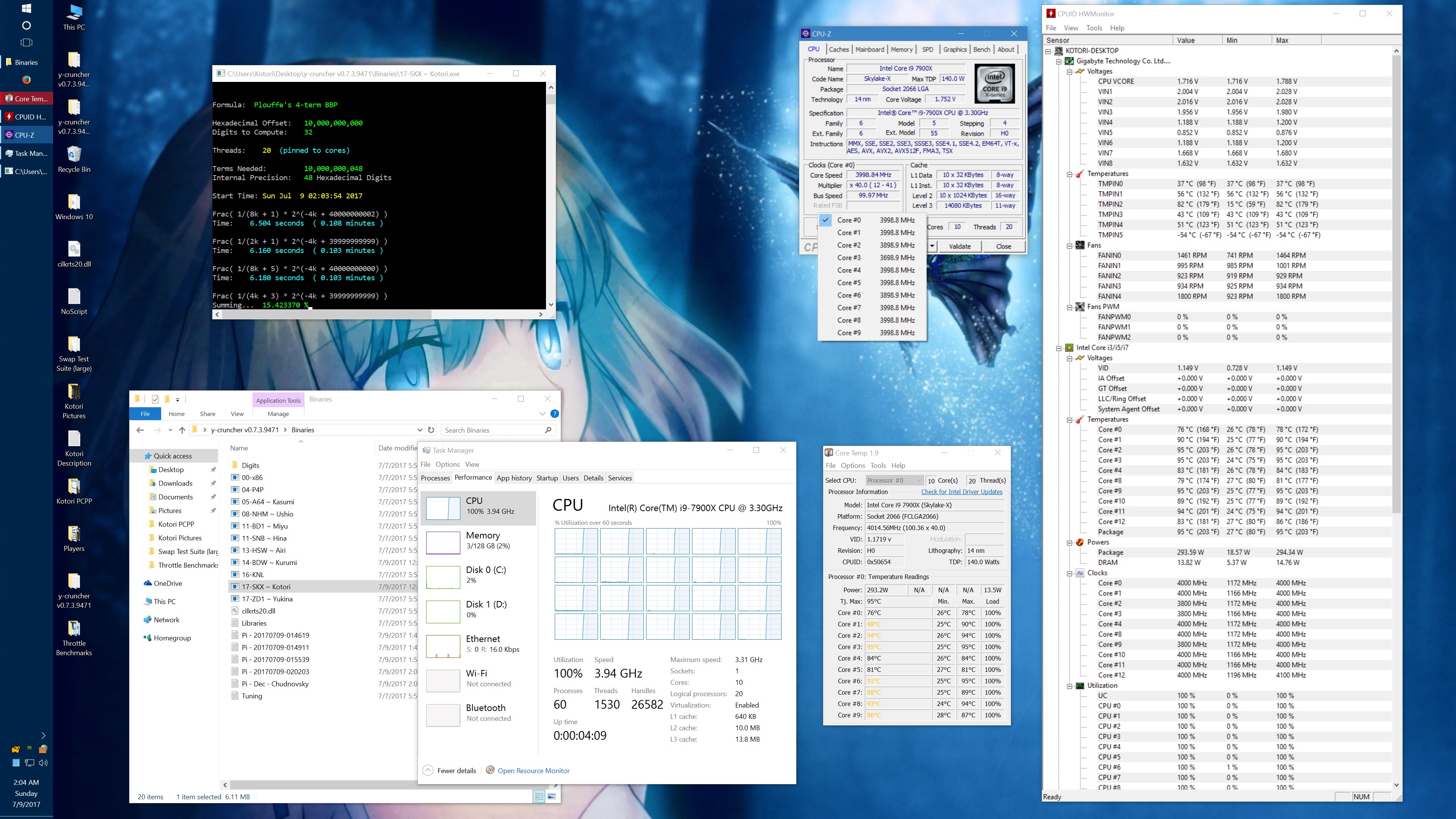
And here's the same set of benchmarks with the throttling eliminated with the appropriate BIOS settings. (Thanks to the guys on Overclock.net for helping me here.) The two benchmarks which phantom throttled before are no longer phantom throttled. But instead, they run hot enough to hit temperature throttling which has a visible drop in frequency.
10 billion Hex-Digit of Pi - Plouffe's 4-term BBP Formula (y-cruncher v0.7.3) Core i9 7900X - Gigabyte AORUS Gaming 7 (BIOS F7a) |
||||||||
Package Power Limit1/2 = 400 W CPU VCore Loadline Calibration = Medium CPU VCore Current Protection = High AVX and AVX512 capped at 4.0 GHz (turbo set to flat 41x, AVX + AVX512 offsets set to 1x) All other settings left at default. |
||||||||
| Binary: | AVX2 (14-BDW) | AVX512 (17-SKX) | ||||||
| Threads/Cores | Time (secs) | Clock Speed | Power | Max Temperature | Time (secs) | Clock Speed | Power | Max Temperature |
| 1 thread/1 core | 454.325 | 4.0 GHz | 48 W | 53°C | 239.082 | 4.0 GHz | 58 W | 70°C |
| 2 threads/2 cores | 228.641 | 4.0 GHz | 62 W | 55°C | 119.740 | 4.0 GHz | 80 W | 74°C |
| 4 threads/4 cores | 113.700 | 4.0 GHz | 94 W | 59°C | 59.900 | 4.0 GHz | 134 W | 74°C |
| 8 threads/8 cores | 57.146 | 4.0 GHz | 159 W | 67°C | 30.061 | 4.0 GHz | 239 W | 95°C |
| 10 threads/10 cores | 46.033 | 4.0 GHz | 191 W | 68°C | 24.340 | 3.8 - 4.0 GHz | 283 W | 95°C |
| 20 threads/10 cores | 42.143 | 4.0 GHz | 209 W | 73°C | 24.972 | 3.7 - 4.0 GHz | 294 W | 95°C |
It's worth noting that there is something wrong here. At stock settings, the motherboard/BIOS is failing to apply the AVX/AVX512 offsets in most of the tests here. This allows all cores to run at 4.0 GHz under AVX512 which is causing the throttling. Furthermore, it allows individual cores to turbo up to 4.5 GHz under AVX512. In other words, the motherboard is overclocking the procesor by default.
The problem with my chip is that the "weakest" core cannot run AVX512 @ 4.5 GHz at default voltages. Doing so will crash (BSOD) the system. Therefore, I had to manually cap the AVX and AVX512 clocks to 4.0 GHz.
While I've fixed this by manually setting the AVX/AVX512 offsets, I hope that a BIOS update will fix this for everyone else who hasn't (or doesn't know to) do this. Dropping the all-core AVX512 clock speed down to 3.6 GHz was enough to avoid all throttling with the default thermal limits.
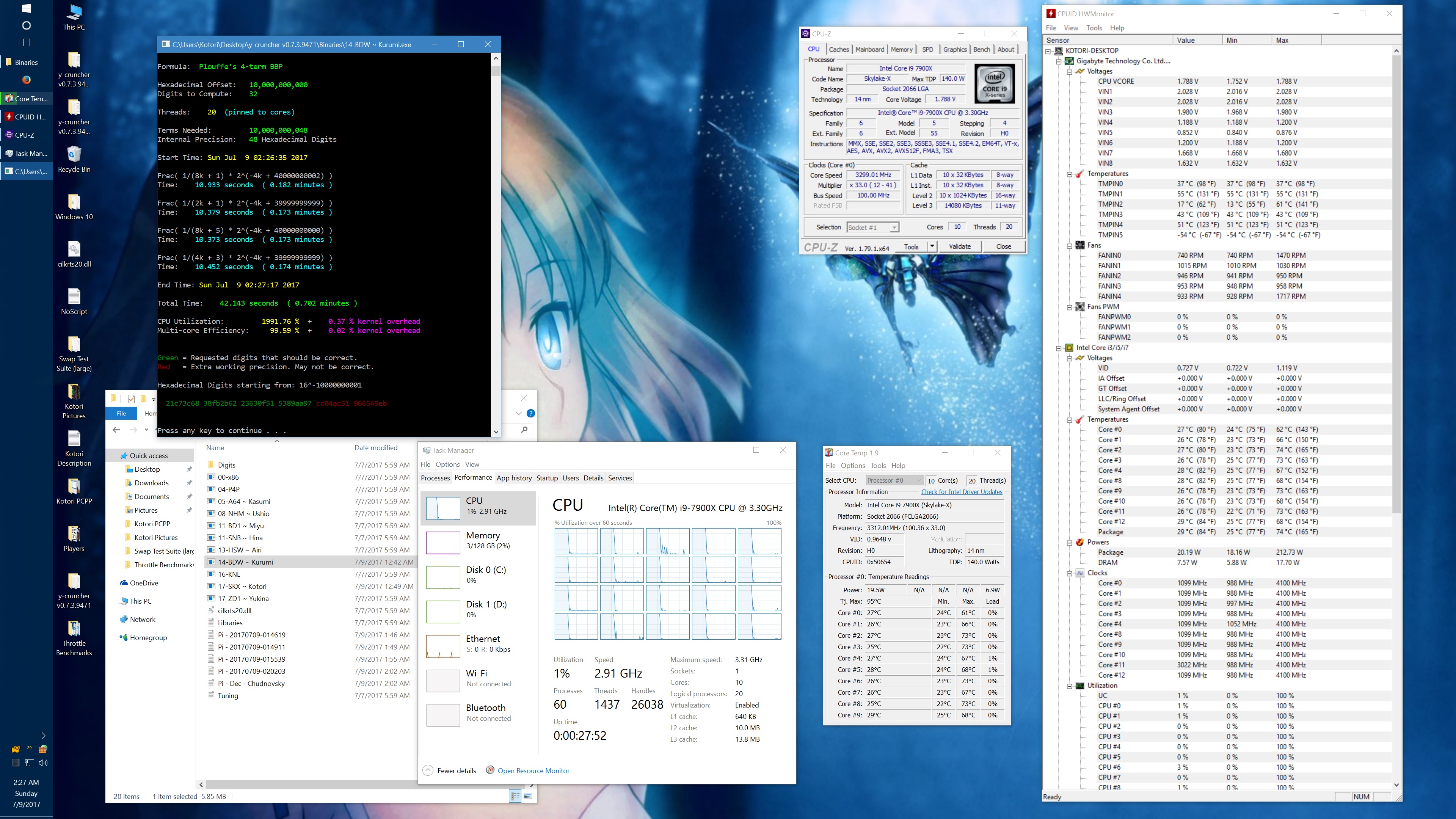
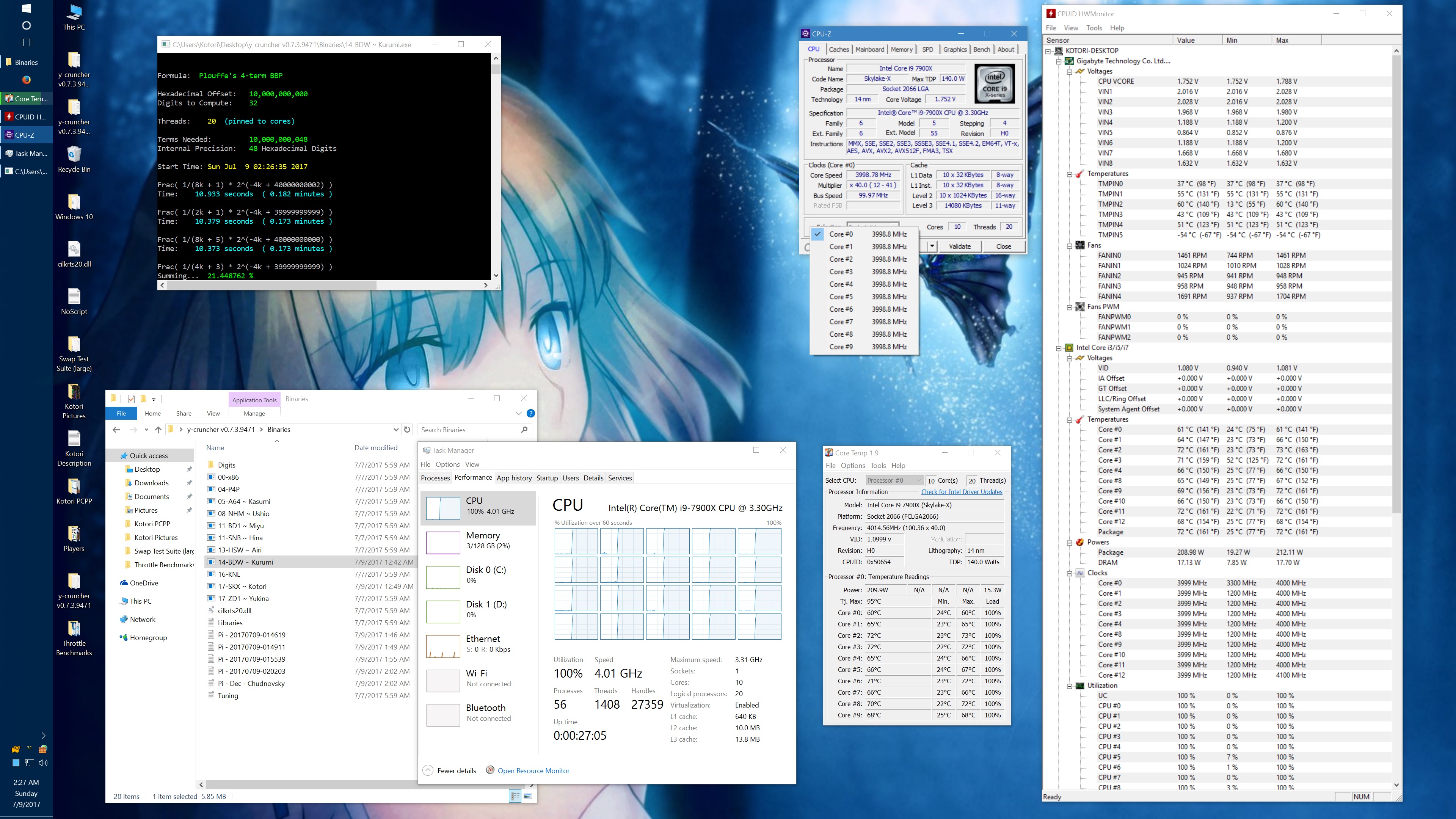
Memory bandwidth is a significant bottleneck:
y-cruncher was already slightly memory-bound on Haswell-E. Now on Skylake X, it is much worse. While I had anticpiated a memory bottleneck on Skylake X with AVX512, it seems that I've underestimated the severity of it:
(The CPU frequencies in this benchmark were chosen to be low enough to avoid any throttling or phantom throttling.)
1 billion digits of Pi - Core i9 7900X @ 3.8 GHz Times in Seconds |
|||
| Threads | Memory Frequency | Instruction Set | |
| AVX2 | AVX512 | ||
1 thread |
2133 MHz | 444.434 | 325.543 |
| 3200 MHz | 438.432 | 319.737 | |
20 threads |
2133 MHz | 51.884 | 45.658 |
| 3200 MHz | 47.672 | 39.723 | |
In the single threaded benchmarks, the memory frequency has less than 2% effect for both AVX2 and AVX512. Multi-threaded, that jumps to 9% and 15% respectively. This is much more than is expected for a program that used to be completely compute-bound just a few years ago.
Amdahl's law and other unknown scalability issues:
In a typical y-cruncher computation, only about 80% of the CPU time is spent running vectorized code when AVX2 is used. So by Amdahl's law, even if we get perfect scaling with the AVX512, we can only cut 40% off the run-time. Right now, the single-threaded benchmarks (which are least memory-bound) are only showing 27% speedup with AVX512 over AVX2.
This remaining 13% discrepancy is currently unresolved. Microbenchmarks of y-cruncher's AVX512 code show near perfect 2x speedups over AVX2. (Some show >2x thanks to the increased register count.) But this speedup seems to drop off as the data sizes increase - even while still fitting in cache. This seems to hint at unknown bottlenecks within the L2 and L3 caches. The fact that cache sizes haven't increased along with wider the SIMD also doesn't help.
For now, investigation is difficult because none of my performance profilers support Skylake X yet.
Implications for Stress-Testing:
y-cruncher's failure to achieve a decent speedup for AVX512 also means that it is unable to put a heavy load on the AVX512 computation units. Therefore it is not a great stress-test for Skylake X with full AVX512.
But there is one y-cruncher feature which seems to be unaffected - the BBP benchmark.
The BBP benchmark feature is contained entirely in cache is thus free of the memory bottleneck. It is able to put a much higher stress than the stress-tester and the computations. So if you run the BBP benchmark (option 4) and set the offset to 100 billion, you can still put a pretty heavy load on your AVX512-capable processor.
A future version of y-cruncher will revamp the stress-tester to incorporate the BBP benchmark as well as other possible improvements.
Version 0.7.2 and AMD Zen: (March 14, 2017) - permalink
I went through a lot of trouble to do this in time for Pi day, but here it is. y-cruncher v0.7.2 has a new binary specifically optimized for AMD's Ryzen 7 processors.
The performance gain is about 5% over the Broadwell-tuned binary and 15% over v0.7.1. It turns out that the optimizations between v0.7.1 and v0.7.2 happened to be more favorable to AMD Zen than to Intel processors. Nevertheless, this is not enough to make Ryzen beat Haswell-E or Broadwell-E.
It's unlikely that any amount of Zen-specific optimizations can make Ryzen beat Haswell/Broadwell-E. The difference in memory bandwidth and 256-bit AVX throughput is simply far too large to overcome. AMD made a conscious decision to sacrifice HPC to focus on mainstream.
As for the Ryzen platform itself: It's a bit immature at this point. I went out on launch day to grab the Zen parts. In the end, it took me 3 sets of memory and 2 weeks before I finally found a stable configuration that I could use. From what I've seen on Reddit and various forums, I've been unlucky, but I'm definitely not alone.
Slightly more concerning is a system freeze with FMA instructions which appears to be have been confirmed by AMD as a processor errata. Fortunately, the source also says this is fixable via a microcode update. So it won't lead to something catastrophic like a recall or a fix that disables processor features.
As for the Zen architecture itself. Here are my (early) observations:
For software developers, compiling code on the 1800X is about as fast as the 5960X at stock clocks. But the 5960X has much more overclocking headroom, so it ends up winning by around 15%. For a $500 processor, the R7 1800X is very impressive.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}