 |
A Peak into y-cruncher v0.6.1 |
 |
By Alexander J. Yee |
(Last updated: May 28, 2012)
y-cruncher v0.6.1 - A Near Complete Rewrite
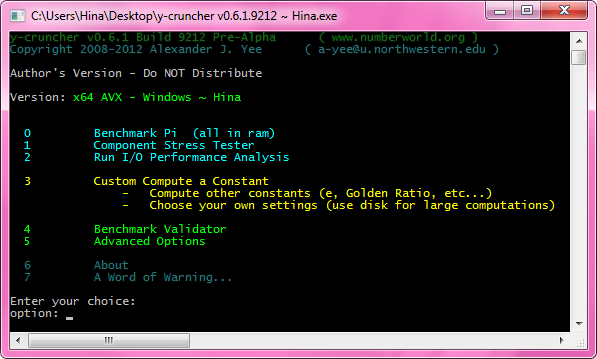
Some time a while ago (probably back in like January 2010) I made the first mention of y-cruncher v0.6.x. And even now it's still far from complete.
v0.6.x is taking so long because it is a near-complete rewrite of y-cruncher. Of the ~178,000 lines of code in v0.5.5, only ~60,000 lines will be reused - half of which will be significantly modified. Progress has been painfully slow since I've been very tied down by school-work.
v0.6.1 is roughly 70% complete. However, the only thing it can compute right now is square roots. Most of the work is in the underlying arithmetic and the frameworks - all of which are needed to compute anything. Since these are mostly done, you could say that v0.6.1 is on the home stretch. Though I can't say when it will be ready since it's uncertain what road-blocks will be encountered.
y-cruncher was originally designed for tens of billions of digits. But in the pursuit of more and more digits, the program has been hacked and retrofitted numerous times to (forcibly) increase this limit to 10 trillion digits. With each change, the program got messier and messier. Much of the code is littered with code-smells from my earlier days as a novice programmer. And many of the original design choices are no longer suitable at 3 orders of magnitude above their initial specifications.
So it's about time to rewrite it properly.
These are the set of changes that are planned for the v0.6.x series of releases. Which and when each of these features will appear is still TBA. But most of the essential features can be expected to appear to in v0.6.1.
(Hint: Anything that is described in detail (especially with screenshots) is probably already done and will likely appear in v0.6.1.)
- New Features:
- Component Stress-Tester: Runs individual algorithms in y-cruncher to stress different parts of the system.
- I/O Benchmark: Benchmarks and evaluates a swap configuration for large computations.
- Multi-layer Raid-File:
- Hybrid RAID 0+3 swap-file management to allow for redundancy while preserving the multi-HD functionality.
- Failed drives can be replaced on the fly without rolling back to a checkpoint.
- Lemniscate Constant: Arc-length of a lemniscate = 5.24411510858423962...
- Swap Mode added for the Euler-Mascheroni Constant.
- Improved Digit Viewer/Compression Format:
- It is no longer necessary to keep all .ycd files in the same folder. This allows the .ycd files to be distributed over multiple drives.
- The new compression format supports a new "extended" format. This allows new digits to be appended to an existing set of .ycd files.
- Removed Features:
- Batch Benchmark Pi
- The current Stress-Tester
- Support for x86 without SSE3.
- Basic Swap Mode
- Changes:
- "Advanced Swap Mode" renamed to simply "Swap Mode".
- Ramanujan's formula for Catalan's Constant will be replaced with Huvent's BBP. (and will support Swap Mode)
- Completely overhauled Benchmark Validation system.
- The digit viewer will be a separate binary.
- Limits:
- All constants will have a hard-limit of 90 trillion digits.
- All constants will have a hard-limit of 90 trillion digits.
- Optimizations:
- x64 XOP: Specially tuned for the AMD Bulldozer processor line.
- Faster Base Conversion.
- Faster Multiplication for large products > 50 billion digits.
- More fine-grained Checkpoint-Restart.
- Raw I/O support for Linux.
- Numerous other minor optimizations.
The reason for dropping everything under "Removed Features" is mainly for practical reasons. Batch Benchmark was never that useful and was just bloating the code-size. The stress-tester is being replaced with a newer one and Basic Swap Mode fell out of use after Advanced Swap Mode was added in v0.5.2.
Dropping support for x86 without SSE3 was not really by choice. Backwards compatibility is great for the fun of running y-cruncher on archaic machines. But for a number of reasons, x86 (no SSE) for v0.6.1 ended up being 30 - 40% slower than on x86 (no SSE) for v0.5.5. And as such, it didn't make much sense to try to reoptimize it up the speed of v0.5.5 for the sake of backward compatibiility. So I decided to just drop it completely rather than have to explain why v0.6.1 is slower than v0.5.5 without SSE.
As mentioned, the only thing v0.6.1 can do right now is square roots. This is it for all the benchmarks for now.
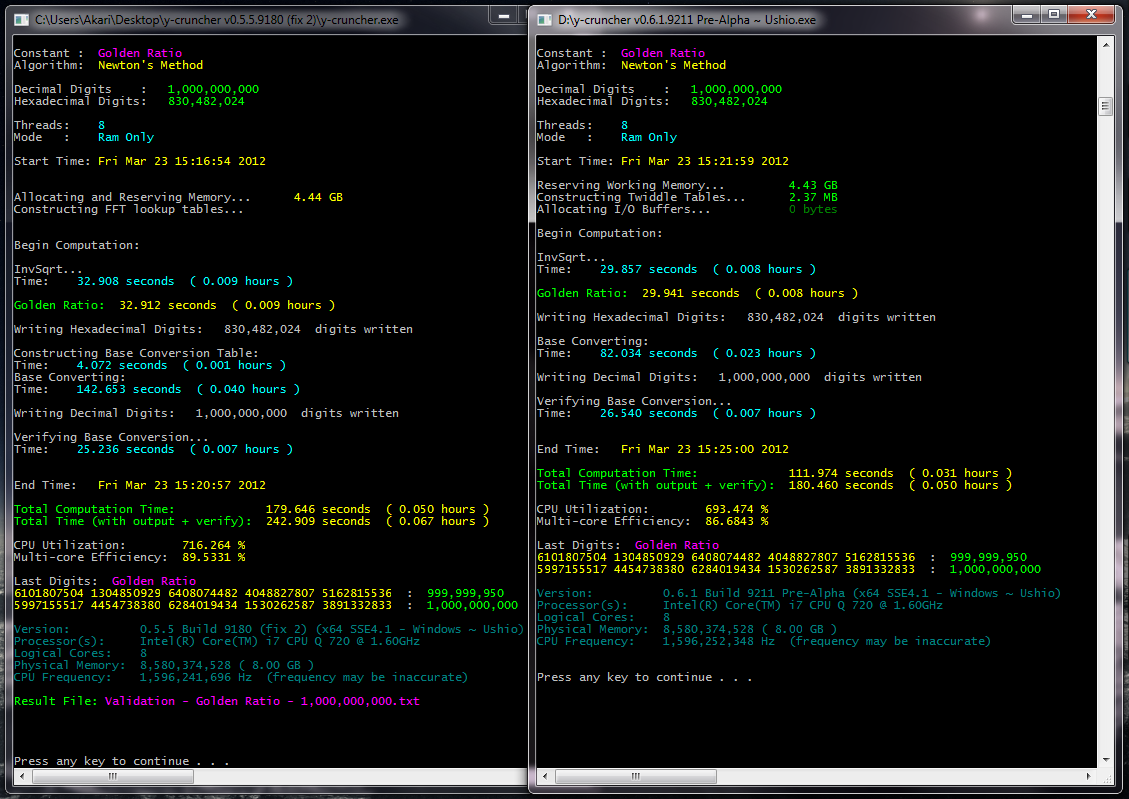
- Speed Comparison: sqrt(2) - v0.5.5 vs. v0.6.1 (credit: Shigeru Kondo)
- 2 trillion digits of sqrt(2): compute / verify - World Record Computation
Both the inverse square root function and the radix conversion have been completely rewritten with numerous optimizations compared to version 0.5.5. So the overall speed-up from v0.5.5 to v0.6.1 for computing square roots is sizable for sufficiently large sizes.
With the new VST Multiplication Algorithm, the larger computation, the bigger the speedup. This has been confirmed by both Shigeru Kondo and myself.
Nevertheless, v0.6.1 is a bit more hungry for disk bandwidth than v0.5.5. So there will be some corner cases where v0.6.1 is actually slower than v0.5.5.
Naturally, this would hurt performance for machines that are completely disk-bound. But such (completely disk-bound) machines won't be able to efficiently run large computations anyway...
Ultimately, no optimizations are planned for the computation of Pi itself in v0.6.x. So whatever speedup that Pi gets will be from the improved subroutines that it calls. The same will apply to most of the other constants.
The coveted GCD factorization is being delayed until v0.7.x due to the sheer number of dependencies that it will have. (e.g. integer division, block sieve, etc...) Furthermore some more work is needed to determine which of the other constants will use GCD factorization as well as how it will be implemented for each of them.
The issue of hard drive reliability was pretty apparent in the 10 trillion digit computation of Pi. Drives were failing every other week and nearly as much time was spent doing roll-backs as was spent doing useful computation.
Aside from the fact that hard drives suck, the main issue is that y-cruncher v0.5.5 only supports a massive RAID-0 array. There were no redundancy options.
Hardware and OS-supported fault-tolerant RAID would solve this problem, but I've found that the performance was usually pretty poor.
(They already sucked with RAID-0, that's why I implemented it natively in y-cruncher in the first place.)
In v0.6.1, the entire raid-file system in y-cruncher has been completely rewritten to support a dual-layer RAID approach.
- The top layer is a RAID-0 array of up to 64 logical drives.
- Each of these logical drives can be either a RAID-0 or a RAID-3 array of up to 8 file-system paths.
(I say file-system paths, since those could also be some OS/hardware RAID of even more drives... But that would be invisible to y-cruncher anyway.) - The setup need not be symmetrical. You can use a combination RAID-0 and RAID-3 in the sub-arrays - and with different # of drives if desired.
Key Points:
- In a pure RAID-0/3 setup, all the sub-arrays are RAID-3. In this setup, the entire array can tolerate up to one failure in each sub-array.
- You can "compensate" for slower drives by grouping them together into their own sub-array.
(For example: 2 fast drives in one sub-array and 3 slow drives in another.)
Failure Handling:
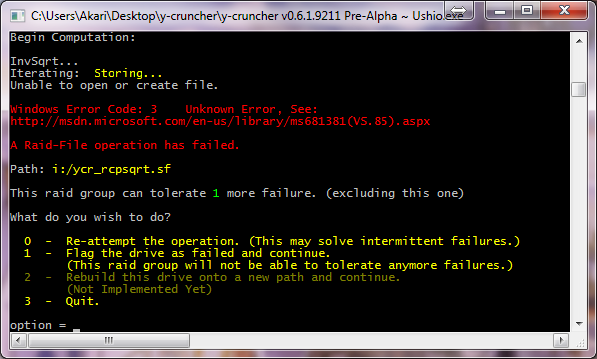
When an I/O failure occurs, the program may prompt the user what to do:
- Re-attempt the operation.
- Disable the drive and continue. (only possible under RAID-3)
- Rebuild the drive on a different path. (only possible under RAID-3)
- Quit
This will allow dead hard drives to be removed or even replaced on the fly without the need to roll the computation back to a checkpoint.
In other cases, (such as a read failure with RAID-3), it will simply recover the data via RAID-3 parity, print a warning message, and continue running as if nothing happened.
Testing the fault-tolerance capability was arguably one of the most amusing parts of v0.6.1... I got to abuse a bunch of hard drives by unplugging them (and re-plugging them) while they were actively running with I/O operations.
In all cases, recovering from a dead drive only seems to work if the port supports plug-and-play. On older machines as well as some on-board SATA ports, the system will simply freeze if you disconnect the drive. I have yet to destroy any hardware like this, but I have triggered some S.M.A.R.T. events in my drives.
Performance:
Intuitively, this dual-layer RAID approach may seem to add unnecessary overhead for RAID-0 only computations. But the lower layer is automatically "turned off" when there is only one drive - thereby disabling the associated overhead.
- RAID-0 performance of v0.6.1 vs. v0.5.5 is faster because the new implementation is more optimized.
- RAID-3 seems to add a roughly 20-40% overhead. Although this is significant, most machines with enough drives to have reliability issues will probably have bandwidth to spare. So hopefully this won't be a problem.
_100b_2012_2_16_kondo.jpg){kind=link}
_100b_2012_2_19_kondo.jpg){kind=link}
/2t_2012_2_4/sqrt(2)_2t_nagisa_2012_2_4.png){kind=link}
/2t_2012_2_4/sqrt(200)_2t_hina_2012_2_9.png){kind=link}
New Digit Viewer + Compression Format
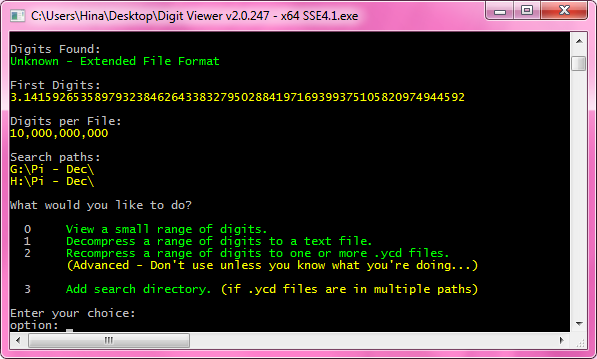
One of the major weaknesses of the .ycd format for compressed files is that you can't "append" new digits without modifying all the existing ones.
This is because each individual .ycd file stores the total # of digits that are in the entire set (among other things). The digit viewer will block the user from attempting to access digits beyond this "total digits" parameter.
Changes:
v0.6.1 will introduce the following changes to the .ycd file format and the digit viewer:
- All the unnecessary information that is embedded in the original .ycd format has been removed.
- The new digit viewer no longer requires that all the .ycd files be in the same folder. They can be distributed across multiple paths. This avoids the need to copy everything to a massive temporary RAID array when reading large datasets that don't fit onto a single hard drive.
- The .ycd format now supports an "extended" mode which will allow an existing set of .ycd files to be extended by simply adding more of them.
For example, suppose 5 trillion digits of Pi are stored in 5 files (0 - 4) with 1 trillion digits per file. Now suppose you compute 10 trillion digits. The extended format will allow you to attach the new files (5 - 9) to the existing ones (0 - 4) and they will be fully compatible. This avoids the need to redistribute the first set of digits if a computation has been improved. (The one requirement is that all the .ycd files need to contain the same # of digits.)
- The numbering systems used in the names for each .ycd file have been relaxed a bit. The new digit viewer no longer requires that the # of digits in the ID be the same for all the .ycd files. In other words, the new digit viewer can tolerate different ID lengths and different counts of leading zeros. (up to a certain point)
For example, both (00, 01, 02, ... , 09, 10, 11, etc...) and (0, 1, 2, ... , 9, 10, 11, etc...) are valid.
The new digit viewer in v0.6.1 will be backwards compatible with the old .ycd file format. But the old digit viewers (in y-cruncher v0.5.5 and early) will not be able to read the new .ycd file format.
Implementation:
Unlike the rest of y-cruncher, the new digit viewer is written in C++. Furthermore, it will have a (reasonably) clean interface and will be open-sourced. This will give everyone access to the optimized compression and decompression routines.
On the other hand, y-cruncher itself will remain a C program. That means that the digit viewer will no longer be integrated into y-cruncher.
It will still be included in the y-cruncher distribution, but will have its own set of binaries and its own CPU dispatcher.
The VST Multiplication Algorithm
Although irrelevant to the casual benchmarker, this will matter for extremely large computations (> 100 billion digits) and is arguably the biggest improvement in v0.6.1.
Prior to v0.6.1, large multiplications relied entirely on the Hybrid NTT algorithm. Although not quite as fast as the floating-point FFT-based algorithms, the Hybrid NTT actually scales with multi-threading. And as such, it has been the backbone of y-cruncher's speed.
But for sizes above 30 billion digits, there are number of problems that start to eat away at its efficiency - eventually slowing it a crawl at around 500 billion digits. I was well aware of this long before Shigeru Kondo and I undertook the 5 trillion digit computation of Pi. But there wasn't anything I could do about it.
So in that sense, both the 5 trillion and 10 trillion digit computations of Pi were
done using very slow methods - yet still state-of-the-art.
To solve this scalability issue, I had to design and implement a new algorithm which I now call, "The VST Multiplication Algorithm". VST is a double acronym for
"Very Stupid Transform" and "Vector-Scalable Transform".
"Very Stupid" because that's what it looks like on paper, and "Vector-Scalable" because it abuses SIMD to the fullest extent so that it isn't so "stupid".
The current heavily optimized implementation stands at 60,000 lines of code. It is somewhat slower than the Hybrid NTT, but it (theoretically) doesn't suffer any slowdown until at least 40 trillion digits. It is 95% floating-point and is highly sensitive to the SIMD capabilities of the machine:
- SSE3 provides ~3 - 4x speedup over x87 FPU.
- SSE4.1 provides 30% speedup over SSE3.
- AVX provides 66% speedup over SSE4.1. (2.16x over SSE3)
- FMA4 + XOP is supported, but currently untested since I don't have an AMD Bulldozer machine.
The crossover point where VST beats Hybrid NTT seems to be about 50 billion digits on both my workstations. Unfortunately, this is well into the swap mode sizes for most machines. So the benefits of the VST algorithm will only be noticable for large computations and when the machine has more disk bandwidth than the computation throughput of the Hybrid NTT.
The algorithm is surprisingly NUMA friendly and scales better than the Hybrid NTT with multiple cores. So a lower threshold may be viable if the Hybrid NTT suffers significantly from NUMA slowdowns.
The VST algorithm comes with two drawbacks. First, it needs more memory than the Hybrid NTT and thus large computations will need more disk space. Secondly the SIMD-heavy aspect of it makes it very stressful on the processor. Last time I checked, it achieves 60 - 70% of peak FLOPS on my machine - not something to be taken lightly in terms heat and power consumption.
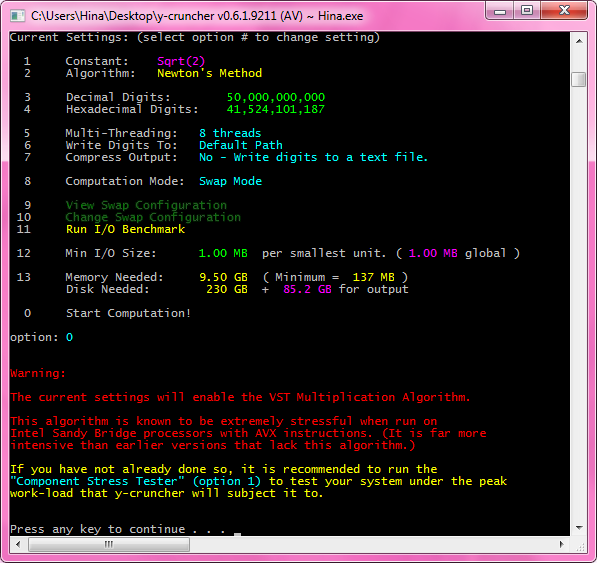
When running on a machine with AVX instructions, v0.6.1 will display a warning message whenever the VST algorithm will be used.
When performing very large computations, it cannot be stressed enough how important disk speed is. Prior to v0.6.1, you could only guess how fast your swap configuration was. And the only way to see how limited you were by disk was to open up Task Manager or wait until the computation was done to see the CPU Utilization.
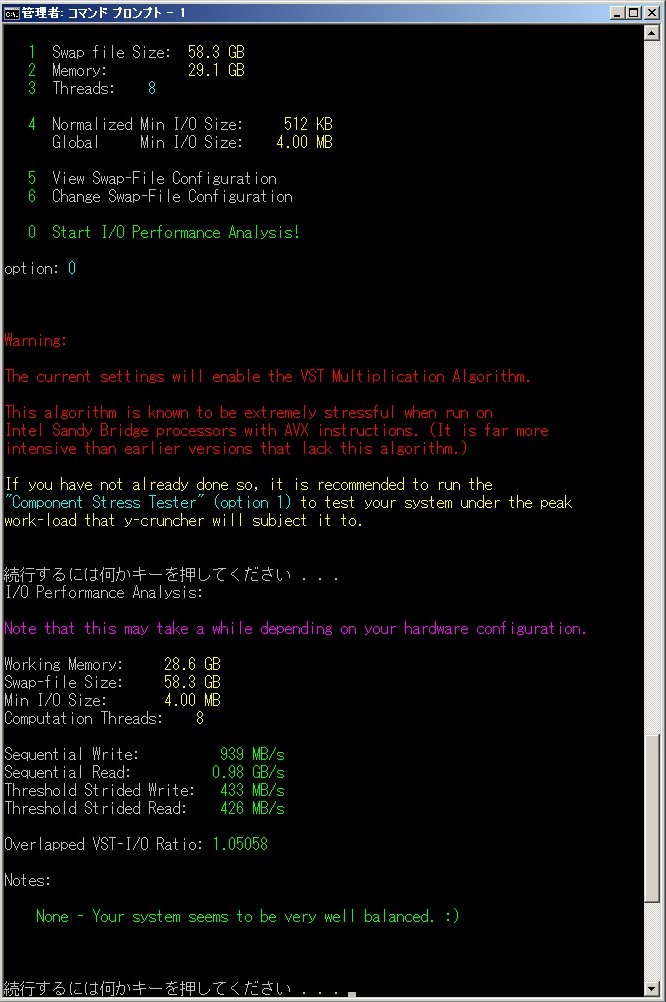
v0.6.1 adds a new I/O benchmark feature to help determine whether or not I/O is a bottleneck - and if so, by how much.
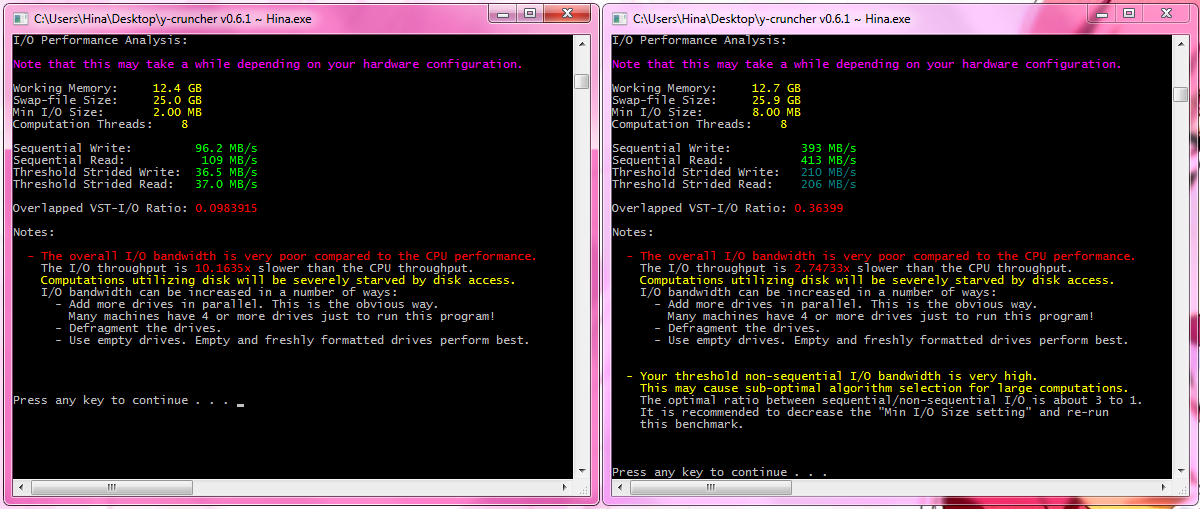
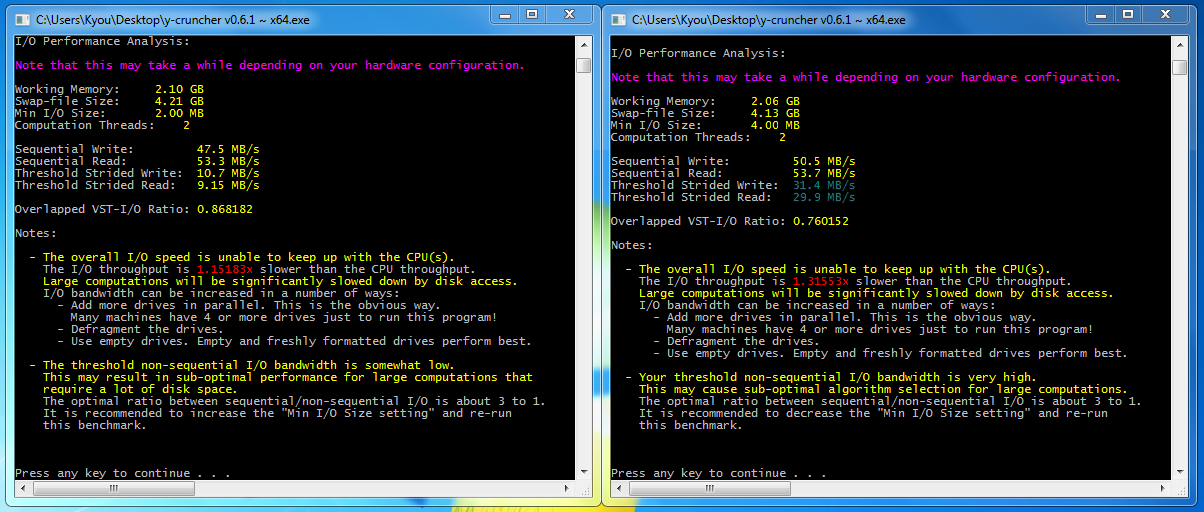
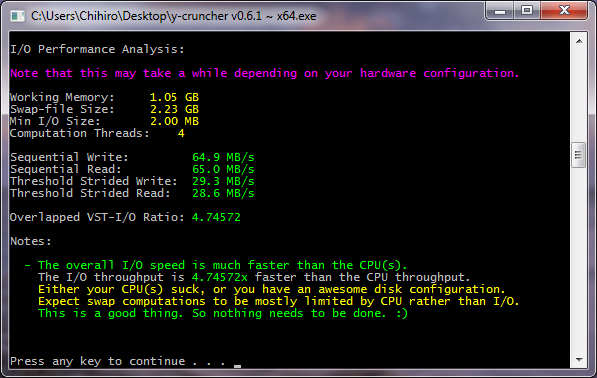
The table should be fairly straight-forward. Blue is good. Red is bad.
| Processor(s) | Clock Speed | Swap Configuration | Seq. Read | Seq. Write | Overlapped IO/Compute* | Credit | Screenshot | Comments |
| Core i7 2700K | 5.0 GHz | 8 x 1 TB | 0.98 GB/s | 939 MB/s | 1.051 | Shigeru Kondo | screenshot | Kondo-san's machines are awesome... |
| Core i7 2600K | 4.4 GHz | 5 x 1 TB + 5 x 2 TB | 873 MB/s | 950 MB/s | 0.960 | Alexander Yee | screenshot | My only well tuned system. |
| 2 x Xeon X5482 | 3.2 GHz | 8 x 2 TB | 836 MB/s | 857 MB/s | 1.443 | Alexander Yee | screenshot | HD slightly faster than CPU |
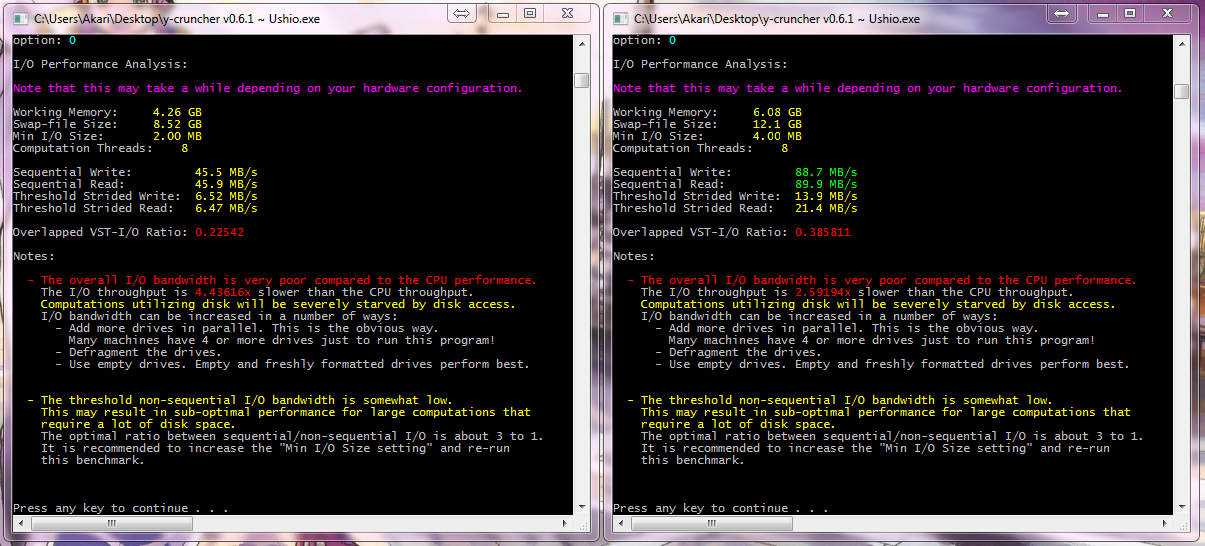
| Core i7 720QM | 1.6 GHz | 500 GB | 45.9 MB/s | 45.5 MB/s | 0.225 | Alexander Yee | screenshot | Laptops suck... |
| 320 GB + 500 GB | 89.9 MB/s | 88.7 MB/s | 0.386 | |||||
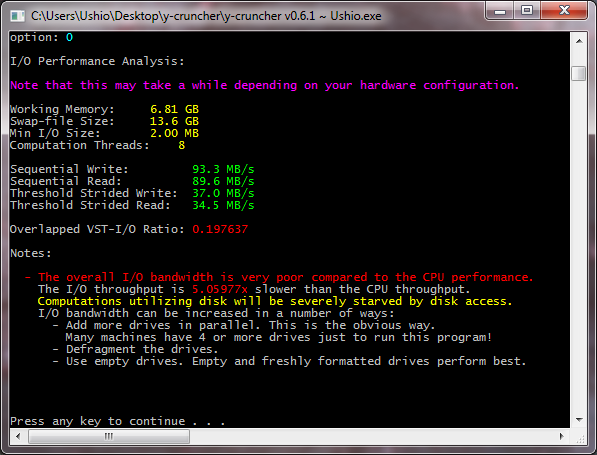
| Core i7 920 | 3.5 GHz | 1.5 TB | 89.6 MB/s | 93.3 MB/s | 0.198 | Alexander Yee | screenshot | One HD won't cut it... |
| Core i7 2600K | 4.4 GHz | 1 TB | 109 MB/s | 96.2 MB/s | 0.098 | Alexander Yee | screenshot | Not even 4 HDs can keep up with the CPU! |
| 4 x 1 TB | 413 MB/s | 393 MB/s | 0.364 | |||||
| Pentium D | 2.8 GHz | 120 GB | 53.3 MB/s | 47.5 MB/s | 0.868 | Alexander Yee | screenshot | Pentiums suck... |
| Atom N550 | 1.5 GHz | 250 GB | 65.0 MB/s | 64.9 MB/s | 4.746 | Alexander Yee | screenshot | Seriously... An Atom processor is almost 5x slower then 1 HD?!?! |
{kind=link}
/2t_2012_2_4/iotest_hina_2012_2_4.png){kind=link}
/2t_2012_2_4/iotest_nagisa_2012_2_4.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
The key number to look at is the "Overlapped IO/Compute" ratio. This is the ratio of I/O speed to the CPU throughput of the VST algorithm.
- Greater than 1.0 means disk speed is faster the CPU speed - computations will be limited CPU.
- Less than 1.0 means disk speed is slower than the CPU - computations will be limited by disk-access.
As you can see, it takes nearly 1GB/s of disk bandwidth to keep up with a modern desktop CPU. That's about 8 high-end desktop hard drives... not cool...
So a typical single hard drive computer that you buy off the shelf is unlikely to be up to the task of computing anything that doesn't fit in ram. It goes to show how far hard drives have lagged behind processors in recent years.
So the point of the benchmark is really to tell you whether or not your system is fit to run a large swap computation. And as such, if you plan on running a gargantuan computation, you can use the I/O benchmark to help build a well-balanced system.
Early in the development of the VST algorithm, it became apparent that it would be the most stressful (non-artificial*) algorithm that I have ever implemented to date.
(*It's trivial to write an artificial task that achieves peak FLOPs and produces tons of heat. See my answer to this Stackoverflow question for an example.)
When I first tested a micro-benchmark of the inner-loop with 8 threads and AVX on my Sandy Bridge machine, it shot the CPU temperatures almost to 90C.
Needless to say, I basically freaked out... But more importantly, I recognized that this could potentially be dangerous...
The problem is that the VST algorithm is only enabled at 50+ billion digits. So the existing stress-tester will never call the VST algorithm. (unless the machine happens to have 200+ GB of ram) So I can see the following scenario happening:
- User uses the existing stress-test to test an overclocked system. User sees the hardware is (borderline) safe and thinks it's stable enough.
- User proceeds to run a large computation (> 50 billion digits). The VST algorithm is enabled at such large sizes.
- Since the VST algorithm is much more stressful than the stress-test itself, the CPU overheats, burns up, and takes the motherboard down with it.
Even though the program is already littered with the disclaimer, "Use y-cruncher at your own risk.", it's basically the same stupid message you see in nearly every single piece of free software. So it's crying wolf - nobody takes it seriously... Especially since previous versions of y-cruncher didn't really have this "problem".
So I felt the need to take an extra step to keep someone from accidentally destroying their (potentially expensive) hardware. Thus I made a new stress-tester.
The new stress-tester tests each of the individual multiplication algorithms that will be used in v0.6.1. Different algorithms stress different parts of the processor to varying degrees. The new stress-tester will let the user see the effects of each algorithm. (Most importantly, it's to let the user run the VST algorithm on demand.)
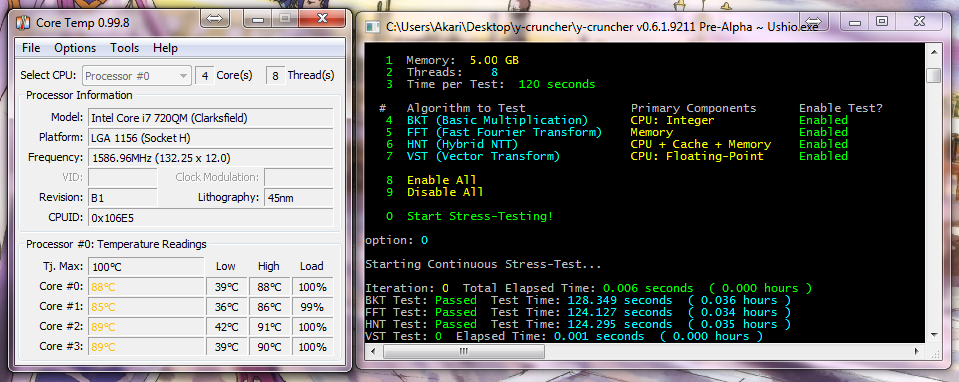
For now, my plans call for the existing stress-tester to be removed. Though I might decide to keep it as an extra option that user can pick from.
Long story short, there will be quite a few things new to v0.6.1... which is somewhat inevitable for a rewrite.
Overall, v0.6.1 will look and feel much the same as earlier versions. But underneath, it's almost a completely different program.
Contact me via e-mail. I'm pretty good with responding unless it gets caught in my school's junk mail filter.